




前段时间又开始写爬虫了,在整理代码时找到了很久之前写的一个小工具:一个基于路径查询Json数据的工具。
当时还没有ChatGPT,是纯手工打造的匠心代码😋,最近又找出来重构更新了一下,所以我干脆写篇文章来记录一下设计思路。
之前在采集某个平台的数据的时候,发现从接口获取到的数据杂乱无章,一层套一层,各种格式也很混乱,如果要从这些数据中获取到指定的字段,就需要套大量的.get().get().get()...最终导致代码也很混乱,可维护性降低。
基于这个需求,我当时想着搞一个可以方便快捷的获取某个字段的工具。(当时还不知道有Json Path这种东西,也没想着去搜一搜,可能就是码瘾犯了就想写点东西吧...)不过虽然这篇文章的标题叫“基于路径的JSON解析工具实现”,但实际上查询json数据的功能本身不太重要,本文重点是如何对查询语句进行解析。
注意:
目前来说该模块(几乎)所有功能Json Path都可以实现,所以如果有此类需求请直接使用更加标准化的Json Path,该模块用来研究和学习即可。
基本功能
先来了解一下这个模块可以实现哪些功能,然后基于这些功能说明一下具体是如何进行实现的。
下面使用的查询语句都是以这段代码结构为例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | # 用于测试的示例JSON数据 test_data = { "root": { "root_key": "root_value", "child": [ ["first", "second"], ["third", "fourth"] ], "key.01": "value", "key[02]": "value2", ".": "pass", "exception": {"error": "trigger"}, "data": [{"id": 1}, {"id": 2}, {"id": 3}], "info": {"list": ["first_list_item", {"details": "detail_value"}]}, "empty": [], "items": [ { "value": 10, "sub_value": 100 }, { "value": 20, "sub_value": 200 }, { "value": 30, "sub_value": 300 } ], "array": [['a', 'b', 'c'], ['d', 'e', 'f']], "dictionary": {"key": "value", "invalid": None}, "list": [ {"id": 1, "name": "value1", "sub_id": "A", "sub_list": [5,6,7,8]}, {"id": 2, "name": "value2", "sub_id": "A", "sub_list": [1,2,3,4]}, {"id": 3, "name": "value3", "sub_id": "B", "sub_list": [9,10,11,12]}, {"id": 2, "name": "value4", "sub_id": "B", "key": True, "sub_list": [5,6,7,8]} ], "number_list": [1,2,3,4,5,6,7,8,9] } } |
基本路径查询
首先是最简单的基本路径查询,使用点表示法(.)或字典键访问语法,用于访问名称符合标准标识符规则(字母、数字、下划线开头,不包含特殊字符)的键。
比如对如上数据,如果你想查询root字典下的root_key的内容,使用以下查询语句:
1 | "root.root_key" |
或者使用Python的字典键访问语法:
1 2 3 4 5 6 | 'root["root_key"]' # 或者使用单引号 "root['root_key']" # 需要注意Python字符串引号嵌套的问题 ".['root']['root_key']" # 连续方括号查询,第一级使用方括号查询需要以点符号开头,其作用同下一条 "*.['root']['root_key']" # 以通配符开头,使用通配符返回当前层级所有数据 |
上述几种方法效果相同,都可以得到查询结果: root_value
对于有特殊符号的查询路径,需要使用方括号查询,如下:
1 2 3 4 | "root['.']" # 以及 "root['key.01']" "root['key[02]']" |
原本是实现了转义符\对点操作符和方括号进行转义的,比如 root.key\.01 这种语法,但在重构1后这种语法不再被支持了。
列表索引和切片
除了对字典键的查询外,还支持对列表的索引和切片,索引和切片必须通过方括号来使用,而不能使用点表示法。
比如对number_list进行索引,如果需要查询下标为2的元素,直接使用如下语句即可:
1 | 'root.number_list[2]' |
支持Python语法的基础切片模式,比如如下语法,这些就不多说了:
1 2 3 4 5 6 7 8 9 10 11 12 | "root.number_list[1:4]" # 基本切片 "root.number_list[::2]" # 步长为2 "root.number_list[::-1]" # 反向切片 "root.number_list[-3:]" # 负数索引 "root.number_list[:3]" # 省略start "root.number_list[3:]" # 省略end "root.number_list[1:6:2]" # 完整切片语法 "root.number_list[10:20]" # 超出范围的切片 "root.number_list[-10:-5]" # 修正期望值 "root.number_list[5:2:-1]" # 反向步长切片 "root.number_list[2:5:0]" # 步长为0(非法) "root.number_list[2:5:1.5]" # 非整数步长(非法) |
基本条件查询
除了上述基本查询外,还支持基于比较符、逻辑运算符的条件查询,通过构建查询表达式来获取数据,比如:
1 2 3 4 5 | "root.list['sub_id'=='A'].sub_list" 'root.list["id"<3].name' 'root.list["id"==2&&"name"=="value4"].sub_list' 'root.list["id"==2||"id"==3].sub_id' 'root.list[("id"==2||"id"==3)].sub_id' |
以 "root.list["id"==2&&"name"=="value4"].sub_list" 为例,这段语句与json path中 $.root.list[?(@.id == 2 && @.name == "value4")] 功能一致,也就是查询list下id为2,name为value4的sub_list值,查询结果应该是 [[5, 6, 7, 8]] 注意是一个二维数组,一层是list的数组,一层是sub_list的数组。
其他几条语句类比即可。
同时,可用使用括号来指定运算优先级,如下语句:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | data = { "list": [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20], "items": [ {"type": "B", "name": "value1", "age": 10}, {"type": "A", "name": "value2", "age": 20}, {"type": "B", "name": "value3", "age": 30}, {"type": "A", "name": "value4", "age": 40}, {"type": "B", "name": "value5", "age": 50}, ] } path = "items[('type'=='A' && 'age'<25) || ('age' >= 40 && 'type'=='B')].name" # 这条语句的查询结果应该是['value2', 'value5'] |
脚本2、函数调用及变量引用
为了配合条件查询,实现更复杂和更灵活的查询情况,我引入了脚本和变量功能。具体用法是:使用@符号声明一段脚本函数调用,使用$符号对变量进行调用,如下语句:
1 | path = "@get_max(1, $a)" |
上面的语句中用到了get_max函数和a变量,但是在使用前需要先通过脚本管理器对函数和变量进行定义:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | from dictquerier import script_manager, query_json @script_manager.register(name="get_max") def get_max(*args): return max(args) script_manager.define("a", 6) data = { "list": [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20] } path = "list[@get_max(3, 5, $a)]" print(query_json(data, path)) |
上面的代码执行输出结果为7,解析器会先获取$a的值(也就是6),然后执行@get_max(3, 5, 6),得到结果6,最后获取list[6]得到7。
使用@script_manager.register()对函数进行注册,可以通过传递name参数来命名调用名,如果留空name,则会自动获取函数名称作为调用名。
执行函数时,会先检测已经通过@script_manager.register()进行注册的函数,如果没有找到对应的注册函数,则会继续寻找Python内置函数或尝试对函数进行导入,比如如下代码:
1 2 3 4 5 6 7 8 9 | from dictquerier import script_manager, query_json # data 不重要,没有用到 data = { "list": [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20] } path = "@random.randint(1, 10)" print(query_json(data, path)) |
这段代码会尝试导入python的random模块,然后调用randint,最后返回一个1到10之间的随机整数;因为random是python的内置包,所以即使该脚本即使没有通过脚本管理器注册,也可以使用。
实现原理
接下来详细说明一下这个解析器是如何实现的。
早期实现方案
在最早期时,因为只是为了做一些简单的路径查询,只支持了点路径语法 "path.to.data",因为语法复杂度不高,所以直接手搓了一个简易的有限状态机3,简单来说就是逐字母扫描,扫描到的每个字母都保存在缓冲区中,如果遇到点符号(".")则将缓冲区中的字符串作为一个整体(我称其为元素),然后清空缓冲区继续扫描,直到完成整个查询语句的处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | # 伪代码,并非完全逻辑 def parse_path(path_str: str) -> list[str]: buffer = "" # 临时存储当前路径元素的字符 elements = [] # 存储解析后的路径元素列表 for char in path_str: if char == ".": # 遇到分隔符时将缓冲区内容存入列表 elements.append(buffer) buffer = "" else: # 非分隔符时累积字符到缓冲区 buffer += char # 处理最后一个元素(点号后的剩余内容) if buffer: elements.append(buffer) return elements |
使用这种方式开发简单,速度快,在O(1)的时间复杂度的情况下就可以完成整个语句的扫描。在扫描完成后,再循环所有元素,直接使用items[element]的方式进行获取。
但是很快这种方法就无法覆盖需求了。一般来说,从接口请求回来的数据不太可能都只有一条,所以我需要引入索引的方式对列表进行处理。于是我对基础语法进行了扩展,引入了方括号来进行下标索引,语法格式为 "path.to.items[index]",其中index为一个整数。为了处理这种结构,对循环体进行了修改,引入了对方括号的检测。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | # 伪代码,并非完全逻辑 def parse_path(path_str: str) -> list[str]: buffer = "" # 临时存储当前路径元素的字符 elements = [] # 存储解析后的路径元素列表 total_length = len(path_str) char_index = 0 while char_index < total_length: char = path_str[char_index] if char == ".": if buffer: elements.append(buffer) buffer = "" elif char == "[": elements.append(buffer) buffer = "" char_index += 1 while path_str[char_index] != "]": buffer += path_str[char_index] char_index += 1 elements.append(int(buffer)) buffer = "" else: buffer += char char_index += 1 # 处理最后一个元素(点号后的剩余内容) if buffer: elements.append(buffer) return elements |
最后在查询时,在使用items[element]时先判断element是一个整数还是字符串,如果是字符串就是用item.get(),如果是整数索引就使用items[element]进行下标查询。
完成整数索引后,我又遇到了新的需求。某组数据中同时存在有效数据和无效数据,数据是否有效是通过某个字段来进行标记的,所以我需要增加一种过滤查询的方法,以实现按照指定条件进行查询,语法为 "path.to.items['type'=='A']"。同时既然有等于(==),那也应该引入>、<、!=、>=、<=等比较操作符。按照这种语法,解析器就需要进行更加复杂的构造。
为了方便对形如'type'=='A'的表达式进行管理,我创建了一个类专门用于表示表达式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 | class Opreater(Enum): """ Operator 枚举类 用于定义支持的操作符类型,便于后续表达式解析和判断。 """ EQUAL = "==" NOT_EQUAL = "!=" LESS_THAN = "<" GREATER_THAN = ">" LESS_EQUAL = "<=" GREATER_EQUAL = ">=" LOGICAL_AND = "&&" LOGICAL_OR = "||" SLICE = "slice" def __str__(self): return self.value class Expression: operator_funcs = { Opreater.EQUAL: lambda x, y: x == y, Opreater.LESS_THAN: lambda x, y: x < y, Opreater.GREATER_THAN: lambda x, y: x > y, Opreater.LESS_EQUAL: lambda x, y: x <= y, Opreater.GREATER_EQUAL: lambda x, y: x >= y, Opreater.NOT_EQUAL: lambda x, y: x != y, } complex_operator_funcs = { Opreater.LOGICAL_AND: lambda x, y: x.right.operate(x.left.operate(y)), Opreater.LOGICAL_OR: lambda x, y: x.left.operate(y) + x.right.operate(y), } def __init__(self, key=None, operator=None, value=None, left=None, right=None): self.key = key self.operator = operator self.value = value self.left: Expression = left self.right: Expression = right def __repr__(self): if self.key: return f'Expression({self.key} {self.operator} {self.value})' elif self.value is not None: return f'Expression(value={self.value})' else: return f'({self.left} {self.operator} {self.right})' |
我将运算符分为三类,一类是比较运算符,一类是逻辑运算符,还有一类是特殊的切片。对于这三类运算符,实际进行的运算操作也不同。对于比较标识符,其输入是需要处理的数据的key,以及目标值,输出是一组符合规则的数据,而逻辑运算符的输入则是两组数据,输出的数据是对这两组数据进行取交集和取并集的合集运算。至于切片运算符,则是和python自带的切片一样,这个就不多说了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 | class Opreater(Enum): ... def get_expression(self): if self.key: value = f'"{self.value}"' if isinstance(self.value, str) else self.value return f'"{self.key}" {self.operator} {value}' elif self.value is not None: return self.value else: return f'({self.left.get_expression()} {self.operator} {self.right.get_expression()})' def operate(self, data): # 基本运算符 if self.operator in self.complex_operator_funcs: return self.complex_operator_funcs[self.operator](self, data) # 逻辑操作符 if self.operator in self.operator_funcs: itempack_list = [] for item_pack in data: result = query_json(item_pack, self.key, no_path_exception=True) if self.operator_funcs[self.operator](result, self.value): itempack_list.append(item_pack) return itempack_list # 切片索引 if self.operator == Opreater.SLICE: return data[self.value] else: raise SyntaxError(f"不支持的运算符: {self.operator}") @staticmethod def parse(expression: str) -> "Expression": expression = expression.strip() if expression.startswith("(") and expression.endswith(")"): return Expression.parse(expression[1:-1]) index, operator = Expression.find_outer_operator(expression) if index != -1: return Expression(left=Expression.parse(expression[:index].strip()), operator=operator, right=Expression.parse(expression[index+len(operator.value):].strip())) # 处理比较表达式 match = re.match(r'("[^"]+"|\'[^\']+\')\s*(==|!=|<=|>=|<|>)\s*(\d+|"[^"]+"|\'[^\']+\'|true|True|False|false|None|null)$', expression) if match: key, operator_str, value = match.groups() key = key.strip("'").strip('"') value = value.strip("'").strip('"') if value.isdigit(): value = int(value) elif value.startswith('"') or value.startswith("'"): value = value[1:-1] # 去除引号 # 将字符串运算符转换为枚举 operator = None for op_enum in Opreater: if op_enum.value == operator_str: operator = op_enum break if operator is None: raise SyntaxError(f"未知的运算符: {operator_str}") return Expression(key=key, operator=operator, value=value) # 处理简单文本或数字索引 # 简单数字索引 if expression.isdigit(): return Expression(value=int(expression)) # 双引号文本字符串 if re.match(r'^"[^"]*"$', expression): return Expression(value=expression.strip('"')) # 单引号文本字符串 if re.match(r"^'[^']*'$", expression): return Expression(value=expression.strip("'")) # 简单文本 if re.match(r'^\w+$', expression): return Expression(value=expression) # 单个通配符 if expression == "*": return Expression(value="*") # 处理复杂切片索引 try: tree = ast.parse(f"__slice_check_{''.join(random.choices(string.ascii_letters + string.digits, k=8))}__[{expression}]", mode='eval') except Exception as e: # 这里是最后一步解析,如果到这一步都解析失败,说明是无效表达式 raise SyntaxError(f"无效表达式: {expression}") if isinstance(tree, ast.Expression) or isinstance(tree.body, ast.Subscript): slice_node = tree.body.slice if isinstance(slice_node, ast.Slice): start = ast.literal_eval(slice_node.lower) if slice_node.lower else None end = ast.literal_eval(slice_node.upper) if slice_node.upper else None step = ast.literal_eval(slice_node.step) if slice_node.step else None if not (isinstance(start, int) or start is None) or not (isinstance(end, int) or end is None) or not (isinstance(step, int) or step is None): raise ValueError(f"切片索引必须是整数或None: [{expression}]") if step == 0: raise ValueError(f"切片步长不能为0: [{expression}]") return Expression(operator=Opreater.SLICE, value=slice(start, end, step)) if isinstance(slice_node, ast.Tuple): # TODO 实现扩展索引(类似list[1,2:3]这种) raise NotImplementedError("扩展索引暂未实现") raise SyntaxError(f"无效表达式: {expression}") @staticmethod def find_outer_operator(expression): """查找表达式中的外层运算符 Args: expression (str): 表达式字符串 Returns: tuple: 包含外层运算符的索引和运算符,如果索引为-1,则表示没有找到外层运算符 """ depth = 0 last_operator_index = -1 operator = None escaped = False for i, char in enumerate(expression): if char == '\' and not escaped: # 这里实际上是两个\,但是代码渲染似乎有些问题,不管几个\都只显示一个 escaped = True continue if char == '(' and not escaped: depth += 1 elif char == ')' and not escaped: depth -= 1 elif depth == 0 and i + 1 < len(expression): # 检查是否是复杂运算符(&&, ||) for complex_op in [Opreater.LOGICAL_AND, Opreater.LOGICAL_OR]: if expression[i:i+len(complex_op.value)] == complex_op.value: last_operator_index = i operator = complex_op break escaped = False return last_operator_index, operator |
其中在处理切片的部分,还偷懒用到了python的抽象语法树(ast模块,后续我们会实现自己的ast模块),这大大减少了手动解析切片的工作量。同时我们需要修改读取字符的循环,让其将表达式从方括号中分离出来,并传输给表达式类进行解析。
最终的表达式类结构是一个标准的树形结构,最外层的叶子节点应该始终是比较表达式,而中间节点应该始终是逻辑表达式4。
随着语法和解析功能的扩展,问题也逐渐显现出来。使用这种方式虽然可以高效处理数据(不过实际上大多数情况使用差别并不大),但是每次引入新的语法就需要更改循环体,并手动增加处理逻辑。这种方式维护性极差,并且随着语法复杂化,状态转移会急剧增长。
为了解决这个问题,我尝试对代码进行了一次重构,完全放弃之前的处理方式,参考一般解释性语言的源代码处理方式5,引入词法、语句分析和抽象语法树(AST)的概念,这将帮助我们能够更好的进行语法和功能的扩展,以及方便地排除错误。
词法分析
词法分析是整个语句处理流程的第一步,其目的是将源代码(查询语句)转换成一组Token。
Token的结构为:
1 2 3 4 5 6 7 8 9 | class Token: def __init__(self, type: TokenType, value, column=None, line=None): self.type = type self.value = value self.line = line self.column = column def __repr__(self): return f'Token({self.type}, {repr(self.value)}, at {self.column} line {self.line})' |
其中使用TokenType来标记Token的类型,TokenType枚举如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | class TokenType(Enum): """ 词法分析器的token类型 """ VARSIGN = ("$", r"\$") # 变量符号,这个符号一般来说后面只能跟NAME SCRIPTSIGN = ("@", r"@") # 脚本符号,这个符号一般来说后面只能跟NAME DOT = (".", r"\.") # . WHITESPACE = ("whitespace", r"\s+") # 空白符,暂时没用,因为在解析时会跳过 OP = ("op", r"==|!=|>=|<=|>|<|&&|\|\||[+\-*/<>]") # 操作符,比如 ==, >, <, *, &&, ||等 NAME = ("name", r"[a-zA-Z_][a-zA-Z0-9_]*") # 标识符 NUMBER = ("number", r"\d+(\.\d+)?([eE][+-]?\d+)?") # 整数或浮点 STRING = ("string", r""""(?:\\.|[^"\\])*"|'(?:\\.|[^\'])*'""") # 引号字符串 LBRACK = ("[", r"\[") # [ RBRACK = ("]", r"\]") # ] LPAREN = ("(", r"\(") # ( RPAREN = (")", r"\)") # ) ASSIGN = ("=", r"=") # = COLON = (":", r":") # : COMMA = (",", r",") # , END = ("EOF", r"$^") # 结束 UNKNOWN = ("UNKNOWN", r".") # 未知字符 def __init__(self, literal, pattern): self._literal = literal self._pattern = pattern @property def literal(self): return self._literal @property def pattern(self): return self._pattern def __repr__(self) -> str: return f"TokenType(literal={self.literal}, pattern={self.pattern})" |
然后需要实现一个词法分析器,将语句字符串转换成由Token类组成的序列,具体思路是:首先对一些特殊的语句进行处理,比如如果语句以点操作符开头,则自动在点操作符前补"*"(通配符);然后将TokenType中各Token类型的pattern生成一个正则组,对语句进行正则匹配。其中,由于END属于控制类符,无需从语句中进行匹配,所以正则规则设置的"$^"6,属于一个永远不会被匹配的占位符。使用finditer方法对规则组进行匹配,同时在匹配时维护行号7和列号,并跳过空格8。
比如对于一段基本上涵盖了目前全部情况(相对来说)较为复杂的语句:
1 | path = ".datas['items'].length['var' != $snum || ("id" >= 3 * 5 && 'age'< @max(10, num2=10 + 5))].n[:15:2]" |
其转换成Token的结果为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | Token(TokenType.OP, '*', at 0 line 1) Token(TokenType.DOT, '.', at 1 line 1) Token(TokenType.NAME, 'datas', at 6 line 1) Token(TokenType.LBRACK, '[', at 7 line 1) Token(TokenType.STRING, "'items'", at 14 line 1) Token(TokenType.RBRACK, ']', at 15 line 1) Token(TokenType.DOT, '.', at 16 line 1) Token(TokenType.NAME, 'length', at 22 line 1) Token(TokenType.LBRACK, '[', at 23 line 1) Token(TokenType.STRING, "'var'", at 28 line 1) Token(TokenType.OP, '!=', at 31 line 1) Token(TokenType.VARSIGN, '$', at 33 line 1) Token(TokenType.NAME, 'snum', at 37 line 1) Token(TokenType.OP, '||', at 40 line 1) Token(TokenType.LPAREN, '(', at 42 line 1) Token(TokenType.STRING, '"id"', at 46 line 1) Token(TokenType.OP, '>=', at 49 line 1) Token(TokenType.NUMBER, '3', at 51 line 1) Token(TokenType.OP, '*', at 53 line 1) Token(TokenType.NUMBER, '5', at 55 line 1) Token(TokenType.OP, '&&', at 58 line 1) Token(TokenType.STRING, "'age'", at 64 line 1) Token(TokenType.OP, '<', at 65 line 1) Token(TokenType.SCRIPTSIGN, '@', at 67 line 1) Token(TokenType.NAME, 'max', at 70 line 1) Token(TokenType.LPAREN, '(', at 71 line 1) Token(TokenType.NUMBER, '10', at 73 line 1) Token(TokenType.COMMA, ',', at 74 line 1) Token(TokenType.NAME, 'num2', at 79 line 1) Token(TokenType.ASSIGN, '=', at 80 line 1) Token(TokenType.NUMBER, '10', at 82 line 1) Token(TokenType.OP, '+', at 84 line 1) Token(TokenType.NUMBER, '5', at 86 line 1) Token(TokenType.RPAREN, ')', at 87 line 1) Token(TokenType.RPAREN, ')', at 88 line 1) Token(TokenType.RBRACK, ']', at 89 line 1) Token(TokenType.DOT, '.', at 90 line 1) Token(TokenType.NAME, 'n', at 91 line 1) Token(TokenType.LBRACK, '[', at 92 line 1) Token(TokenType.COLON, ':', at 93 line 1) Token(TokenType.NUMBER, '15', at 95 line 1) Token(TokenType.COLON, ':', at 96 line 1) Token(TokenType.NUMBER, '2', at 97 line 1) Token(TokenType.RBRACK, ']', at 98 line 1) Token(TokenType.END, 'EOF', at 99 line 1) |
这段表达式一共100个字符,45个Tokens。
语法分析
完成词法分析后,需要进行语法分析,并将词法分析得到的Token序列转换成一种带有语法规则的特定结构。
在早期实现方案中,并没有生成语法规则的步骤,而是按照元素逐个解释,这种实现方法对于语法扩展来说极差,实现任意新的语法都需要对代码进行大量修改;而在这个模块中,Token序列最后会被转换成抽象语法树。
早期的Python9使用手写 LL(1)10 语法分析器,后来引入 match-case、完善的类型提示等越来越多的语法后,使用 LL(1) 难以进行维护,所以在 Python 3.9 以后将解析器替换成了PEG11。相比于LL(1),PEG更加灵活对于复杂语法的开发和维护更加容易,语法表达能力也更加强大。
Python 中的pegen可以通过语法规则生成C语言的处理代码,大多数语法都在cpython/Grammar/python.gram文件中,我之前尝试过给Python增加do while语法功能,就是通过修改该文件来进行语法定义的,不过很可惜当时没有写文章记录修改过程。
不过我的GitHub仓库还留有修改后的源代码(同样的,当时还没有ChatGPT,属于纯手工匠心代码了):我称其为knpython,具体的语法定义如下:
1 2 3 4 5 6 7 8 9 10 11 | # do while 语法规则 do_while_stmt[stmt_ty]: | invalid_do_stmt | 'do' ':' b=block 'while' a=named_expression NEWLINE c=[else_block] { _PyAST_DoWhile(a, b, c, EXTRA) } # do while 错误检测子规则 invalid_do_stmt: | 'do' ':' block 'while' named_expression NEWLINE { RAISE_SYNTAX_ERROR("expected NEWLINE after 'while' condition") } | a='do' ':' NEWLINE !INDENT { RAISE_INDENTATION_ERROR("expected an indented block after 'do' statement on line %d", a->lineno) } | 'do' block 'while' named_expression { RAISE_SYNTAX_ERROR("expected ':' after 'do'") } |
具体的内容就不展开解释了。
实际上,不管是LL(1)还是PEG,实际都是一种语法类别,用于对代码语法进行描述,正如上面的 do while 描述代码正是PEG的描述语法,最终这段语法会被生成实际解析的代码。
不过在这篇文章中,我们不会用到PEG(因为实现起来太复杂了,没必要,后续可能单独写文章来实现),我们选择手动实现一个递归下降解析器。
递归下降解析器
与 LL(1) 和 PEG 不同,递归下降解析器不是语法类型,而是一种解析器实现策略。递归下降解析器将每个语法规则写成一个函数,函数之间递归调用,每个函数试图匹配输入的一部分,如果匹配失败就立即报错。LL(1) 和 PEG12 都可以通过递归下降解析器来实现。
正如其名,递归下降解析器使用递归13的方法来对语句进行处理,在本文实现的解析器中,递归调用处理流程如下:
1 2 3 | 解析逻辑表达式(||, &&) -> 解析比较表达式(>, <, >=, <=, ==, !=) -> 解析加减法表达式(+, -) -> 解析乘除法表达式(*, /) -> 解析路径表达式(obj.key 或 obj[index]) -> 解析基本表达式(变量、脚本调用、字面量等) |
不过由于是递归调用,所以实际上处理流程和上面的箭头是相反的,也就是说是先处理基本表达式,最后处理逻辑表达式。同时在这个调用链的流程中也体现出了整个语句的处理优先级,越往里的越优先处理,比如在处理路径前先解析变量和脚本调用,在处理加减法前先处理乘除法等等。
首先是一些基本操作,比如消耗当前Token、预览下一个Token、检查Token类型等工具方法,实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 | class Parser: """ 递归下降解析器,将Token序列解析为抽象语法树 """ def __init__(self, tokens: Iterator[Token]): self.tokens = [token for token in tokens if token.type != TokenType.WHITESPACE] # 过滤掉所有空白符 self.current = 0 self.current_token = self.tokens[0] if self.tokens else None def parse(self) -> ASTNode: """ 解析入口,解析完整表达式并返回AST根节点 """ if not self.tokens: raise SyntaxError("没有可解析的令牌") # 常规解析 result = self.expr() # 确保所有令牌都已解析(除了END) if self.current_token and self.current_token.type != TokenType.END: self.error(f"解析结束后仍有未处理的令牌: {self.current_token}") return result def error(self, message: str): """抛出语法错误异常""" line = self.current_token.line if self.current_token else "未知" column = self.current_token.column if self.current_token else "未知" raise SyntaxError(f"{message},在行 {line} 列 {column}") def advance(self, offset: int = 1): """前进到下一个令牌""" self.current += offset if self.current < len(self.tokens): self.current_token = self.tokens[self.current] else: self.current_token = None def peek(self, offset: int = 1) -> Optional[Token]: """预览后面的令牌,不消耗当前令牌""" pos = self.current + offset if 0 <= pos < len(self.tokens): return self.tokens[pos] return None def match(self, *types: TokenType) -> bool: """检查当前令牌是否匹配指定类型之一""" if self.current_token and self.current_token.type in types: self.advance() return True return False def expect(self, *types: TokenType) -> Token: """期望当前令牌是指定类型之一,否则报错""" if self.current_token and self.current_token.type in types: token = self.current_token self.advance() return token expected = " 或 ".join(t.literal for t in types) got = self.current_token.type.literal if self.current_token else "EOF" self.error(f"期望 {expected},但得到了 {got}") |
在这段代码中使用到了一个类型 ASTNode,这是专门用于描述AST节点的类,不同节点有不同的结构和参数。下面的代码是所有AST类,包括标识符、数字、字符串、函数、变量等,都是一些结构定义,没有什么逻辑代码,就不展开说明了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 | class ASTNode: """ 抽象语法树节点基类 """ def __init__(self, type_: str, line: Optional[int] = None, column: Optional[int] = None) -> None: self.type: str = type_ self.line: Optional[int] = line self.column: Optional[int] = column def __repr__(self) -> str: return f"{self.type}({self.__dict__})" class NameNode(ASTNode): """ 标识符节点 """ def __init__(self, name: str, line: Optional[int] = None, column: Optional[int] = None) -> None: super().__init__(self.__class__.__name__, line, column) self.name: str = name class NumberNode(ASTNode): """ 数字节点 """ def __init__(self, value: str, line: Optional[int] = None, column: Optional[int] = None) -> None: super().__init__(self.__class__.__name__, line, column) # 处理带负号的数字字符串 self.value: Union[int, float] = float(value) if '.' in value or 'e' in value.lower() else int(value) class StringNode(ASTNode): """ 字符串节点 """ def __init__(self, value: str, line: Optional[int] = None, column: Optional[int] = None) -> None: super().__init__(self.__class__.__name__, line, column) self.value: str = value class VarRefNode(ASTNode): """ 变量引用节点 """ def __init__(self, name: NameNode, line: Optional[int] = None, column: Optional[int] = None) -> None: super().__init__(self.__class__.__name__, line, column) self.name: NameNode = name class ScriptCallNode(ASTNode): """ 脚本调用节点 """ def __init__(self, module: NameNode, name: NameNode, args: List[ASTNode], kwargs: Dict[str, ASTNode], line: Optional[int] = None, column: Optional[int] = None) -> None: super().__init__(self.__class__.__name__, line, column) self.module: List[NameNode] = module self.name: NameNode = name self.args: List[ASTNode] = args self.kwargs: Dict[str, ASTNode] = kwargs |
基本表达式解析
接下来是处理语句的逻辑,我们从内向外实现,首先是基本表达式的解析:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 | class Parser: ... def primary(self) -> ASTNode: """解析基本表达式(变量、脚本调用、字面量等)""" if not self.current_token: self.error("意外结束,期望表达式") token = self.current_token # 检查是否是单独的通配符(*) if token.type == TokenType.OP and token.value == '*': line, column = token.line, token.column self.advance() # 创建一个特殊的通配符节点 # 这里使用一个空的名字,不依赖于特定键名 root_node = NameNode('', line=line, column=column) # 添加一个标记,表示这是根级别的通配符 root_node._is_root_wildcard = True return KeyNode(root_node, '*', is_wildcard=True, line=line, column=column) # 检查负号开头的负数 if token.type == TokenType.OP and token.value == '-': line, column = token.line, token.column self.advance() # 确保负号后面跟着数字 if self.current_token and self.current_token.type == TokenType.NUMBER: number_token = self.current_token value = "-" + number_token.value self.advance() return NumberNode(value, line, column) else: # 如果不是负数,回退到上一个token(负号),让正常的二元运算处理 self.current -= 1 self.current_token = token # 变量引用: $name if token.type == TokenType.VARSIGN: line, column = token.line, token.column self.advance() name_token = self.expect(TokenType.NAME) name_node = NameNode(name_token.value, name_token.line, name_token.column) return VarRefNode(name_node, line, column) # 脚本调用: @func(args) elif token.type == TokenType.SCRIPTSIGN: line, column = token.line, token.column self.advance() module_node = [] name_node = None # 判断是否是"模块.函数"的形式 while not (self.current_token and self.current_token.type == TokenType.LPAREN): next_token = self.peek() if next_token and next_token.type == TokenType.DOT: module_node.append(NameNode(self.current_token.value, self.current_token.line, self.current_token.column)) # 前进两步,跳过"." self.advance(2) else: # 路径最后一级走此分支 name_node = NameNode(self.current_token.value, self.current_token.line, self.current_token.column) self.advance() break if name_node is None: self.error(f"脚本解析失败: 未找到函数名") # 解析参数列表 args = [] kwargs = {} if self.current_token and self.current_token.type == TokenType.LPAREN: self.advance() # 解析参数 if self.current_token and self.current_token.type != TokenType.RPAREN: # 解析第一个参数 if self.current_token and self.current_token.type == TokenType.NAME: # 关键词参数 key_node = self.expr() self.expect(TokenType.ASSIGN) kwargs[key_node] = self.expr() else: # 位置参数 args.append(self.expr()) # 解析逗号分隔的后续参数 while self.current_token and self.current_token.type == TokenType.COMMA: self.advance() if self.current_token and self.current_token.type == TokenType.NAME: # 关键词参数 key_node = self.expr() self.expect(TokenType.ASSIGN) kwargs[key_node] = self.expr() else: # 位置参数 args.append(self.expr()) # 确保参数列表以右括号结束 self.expect(TokenType.RPAREN) return ScriptCallNode(module_node, name_node, args, kwargs, line, column) elif token.type == TokenType.NAME: # 标识符或键名: name name = token.value line, column = token.line, token.column self.advance() return NameNode(name, line, column) elif token.type == TokenType.NUMBER: # 数字字面量: 123, 45.67 value = token.value line, column = token.line, token.column self.advance() return NumberNode(value, line, column) elif token.type == TokenType.STRING: # 字符串字面量: "text", 'text' value = self._parse_string_literal(token.value) line, column = token.line, token.column self.advance() return StringNode(value, line, column) elif token.type == TokenType.LPAREN: # 括号表达式: (expr) self.advance() # 取括号内的内容,按照一段完整语句进行递归处理 expr = self.expr() self.expect(TokenType.RPAREN) return expr else: self.error(f"意外的令牌类型: {token.type.literal}") def _parse_string_literal(self, string_literal: str) -> str: """解析字符串字面量,去除引号并处理转义字符""" # 去除开头和结尾的引号 inside = string_literal[1:-1] # 简单处理转义字符 result = "" i = 0 while i < len(inside): if inside[i] == '\' and i + 1 < len(inside): # 处理转义字符 if inside[i+1] in ('"', "'", '\'): result += inside[i+1] i += 2 else: result += inside[i:i+2] i += 2 else: result += inside[i] i += 1 return result |
在这段代码中,首先会判断当前token的类型,并按照每种类型进行分别处理,并返回对应的最终的节点类型。比如单纯的字面量,当判断token的类型为 TokenType.NUMBER 或 TokenType.STRING 时,就会直接返回对应的 NumberNode 和 StringNode;如果是括号表达式,就会让括号中的语句进行下一层递归处理;如果是操作符,则会先判断是否是通配符("*")或者负号("-"),对于通配符,会创建一个没有名称(NameNode的name为空)的 KeyNode,并且对节点标记 node._is_root_wildcard = True。之所以需要标记 _is_root_wildcard,主要是为了与路径中的通配符进行区分(路径中的通配符会在后面的路径解析中处理),在这个模块中,通配符用于占位根节点或在路径中获取所有数据,比如上面提到的例子 "*.['root']['root_key']" 这里就是对这种情况的特殊处理。
这一步处理中,需要展开说明的是变量和函数的解析,最主要的是函数处理。在这个模块中,变量是以$开头的Name Token,其中$符在进行tokenization时会被识别为 TokenType.VARSIGN,在进行语法解析时,检测到 VARSIGN 就会对后面的 NameToken 进行处理,VARSIGN Token 和后续的 Name Token 会被定义为 VarRefNode。同样脚本(函数)也会进行类似处理,只是会多一步变量解析。在解析脚本时,会先判断脚本是否是”模块.函数()“的格式14。如果是这种格式,则会先把所有的模块分离出来,最后一级处理成函数名,最后在创建脚本调用节点 ScriptCallNode 时会分别传入模块和函数名。同样变量也需要分两种类型处理,一种是仅包含参数值,比如”func(15)“;一种是包含形参名的变量,比如”func(num=15)“,检测到左括号 TokenType.LPAREN 时,会进入参数处理的状态,然后判断 Token 类型,如果是 Name Token 则将其作为带形参名的变量处理,否则直接作为普通参数处理。完成一个参数处理后判断后续是逗号 TokenType.COMMA 还是右括号 TokenType.RPAREN,如果是逗号则继续处理下一个参数,否则完成参数的处理。
路径解析
完成基本表达式的解析后,进入路径解析,并将基本表达式创建的节点作为left(语法树的左分支)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 | class Parser: ... def path(self) -> ASTNode: """解析路径表达式 (obj.key 或 obj[index])""" left = self.primary() def _parse_slice_parts() -> tuple: """ 解析切片的end和step部分 返回: tuple: (end, step) - 切片的end和step部分 """ # 检查是否是第二个冒号,如 [start?::step] if self.current_token and self.current_token.type == TokenType.COLON: # 是 [start?::step] 形式,end为None end = None self.advance() # 跳过第二个冒号 # 解析step,如果有的话 step = self.expr() if self.current_token and self.current_token.type != TokenType.RBRACK else None else: # [start?:end] 形式 end = self.expr() if self.current_token and self.current_token.type != TokenType.RBRACK else None # 检查是否有第二个冒号,如 [start?:end?:] if self.current_token and self.current_token.type == TokenType.COLON: self.advance() # 跳过第二个冒号 step = self.expr() if self.current_token and self.current_token.type != TokenType.RBRACK else None else: step = None return end, step while self.current_token: if self.current_token.type == TokenType.DOT: # 字典键访问: obj.key self.advance() # 检查通配符 obj.* if self.current_token and self.current_token.type == TokenType.OP and self.current_token.value == '*': line, column = self.current_token.line, self.current_token.column self.advance() left = KeyNode(left, '*', is_wildcard=True, line=line, column=column) # 键名可能是NAME或STRING elif self.current_token.type == TokenType.NAME: key_name = self.current_token.value line, column = self.current_token.line, self.current_token.column self.advance() left = KeyNode(left, key_name, line=line, column=column) elif self.current_token.type == TokenType.STRING: key_name = self._parse_string_literal(self.current_token.value) line, column = self.current_token.line, self.current_token.column self.advance() left = KeyNode(left, key_name, line=line, column=column) else: self.error(f"键访问后期望标识符或字符串,但得到了 {self.current_token.type.literal}") elif self.current_token.type == TokenType.LBRACK: # 索引访问: obj[index] line, column = self.current_token.line, self.current_token.column self.advance() # 检查是否是通配符索引 obj[*] if self.current_token and self.current_token.type == TokenType.OP and self.current_token.value == '*': wildcard_token = self.current_token self.advance() # 确保通配符后面是右括号 self.expect(TokenType.RBRACK) # 创建一个特殊的StringNode表示通配符 wildcard_node = StringNode('*', wildcard_token.line, wildcard_token.column) left = IndexNode(left, wildcard_node, line, column) else: # 检查是否是切片 obj[start:end:step] if self.current_token and self.current_token.type == TokenType.COLON: # 是 [:end:step] 形式,start为None start = None self.advance() # 跳过第一个冒号 end, step = _parse_slice_parts() self.expect(TokenType.RBRACK) left = SliceNode(left, start, end, step, line, column) else: # 先解析第一个表达式 index_expr = self.expr() # 检查是否有冒号,表示这是切片的开始 if self.current_token and self.current_token.type == TokenType.COLON: # 是 [start:end:step] 形式 start = index_expr self.advance() # 跳过冒号 end, step = _parse_slice_parts() self.expect(TokenType.RBRACK) left = SliceNode(left, start, end, step, line, column) else: # 普通索引访问 obj[index] self.expect(TokenType.RBRACK) left = IndexNode(left, index_expr, line, column) else: # 不是路径访问操作,跳出循环 break return left |
对于路径的解析,一共有两种情况:一是点操作符,二是方括号。对于点操作符,首先会检查是否是通配符"*",这里的通配符和根节点的通配符功能相同,处理方式也大致一样,之所以分两步处理只是因为通配符所处未知不同,在根目录的通配符需要进行一些路径兼容处理。随后判断是否是Name或者String,分别对应 "path.'to'.data",其中path和data是Name,'to'是String,分两种判断只是对路径中字符串进行一种兼容。而两种类型的Token的处理方式也完全一致,只是String会调用_parse_string_literal来处理掉前后的引号和内部转义符。最后全部处理成 keyNode 作为键节点返回。
对于方括号的处理,方括号中可能有两种情况,一是索引节点 IndexNode,二是切片节点 SliceNode。索引节点不一定单纯指数字索引,也可能包含表达式等,所有表达式节点都会称为 IndexNode 的子节点,后面可以通过分析AST结构来进一步帮助理解,目前先理解成”除切片外所有方括号都算IndexNode“即可。
代码占比比较大的部分是对切片的处理,不过虽然看起来很复杂,实际上也就是暴力涵盖多种情况而已,这还得感谢Python支持切片省略的写法比如 [1::2]、[::3]、[:-1] 等等各种特殊情况都得考虑到。
二元运算
接下来是加减乘除四则运算以及比较表达式和逻辑表达式。按照运算法则,乘除法作为高级运算其优先级应该高于加减法,完成数值运算后进行比较运算,最后进行逻辑运算。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 | class Parser: ... def expr(self) -> ASTNode: """解析逻辑表达式 (||, &&)""" left = self.comparison() while (self.current_token and self.current_token.type == TokenType.OP and self.current_token.value in (Operator.LOGICAL_OR.value, Operator.LOGICAL_AND.value)): # 将操作符字符串转换为Operator枚举 op_value = self.current_token.value op = Operator.LOGICAL_OR if op_value == Operator.LOGICAL_OR.value else Operator.LOGICAL_AND line, column = self.current_token.line, self.current_token.column self.advance() right = self.comparison() left = BinaryOpNode(left, op, right, line, column) return left def comparison(self) -> ASTNode: """解析比较表达式 (>, <, >=, <=, ==, !=)""" left = self.addition() while (self.current_token and self.current_token.type == TokenType.OP and self.current_token.value in ( Operator.GREATER_THAN.value, Operator.LESS_THAN.value, Operator.GREATER_EQUAL.value, Operator.LESS_EQUAL.value, Operator.EQUAL.value, Operator.NOT_EQUAL.value )): # 将操作符字符串转换为Operator枚举 op_value = self.current_token.value op = next(op for op in Operator if op.value == op_value) line, column = self.current_token.line, self.current_token.column self.advance() right = self.addition() left = BinaryOpNode(left, op, right, line, column) return left def addition(self) -> ASTNode: """解析加减法表达式 (+, -)""" left = self.multiplication() while (self.current_token and self.current_token.type == TokenType.OP and self.current_token.value in (Operator.PLUS.value, Operator.MINUS.value)): # 将操作符字符串转换为Operator枚举 op_value = self.current_token.value op = Operator.PLUS if op_value == Operator.PLUS.value else Operator.MINUS line, column = self.current_token.line, self.current_token.column self.advance() right = self.multiplication() left = BinaryOpNode(left, op, right, line, column) return left def multiplication(self) -> ASTNode: """解析乘除法表达式 (*, /)""" left = self.path() while (self.current_token and self.current_token.type == TokenType.OP and self.current_token.value in (Operator.MULTIPLY.value, Operator.DIVIDE.value)): # 将操作符字符串转换为Operator枚举 op_value = self.current_token.value op = Operator.MULTIPLY if op_value == Operator.MULTIPLY.value else Operator.DIVIDE line, column = self.current_token.line, self.current_token.column self.advance() right = self.path() left = BinaryOpNode(left, op, right, line, column) return left |
这四个函数操作几乎完全一致,都是建立一个 BinaryOpNode ,左边是当前待运算的值,右边是递归结果,op则是具体的操作符。这四个函数在构造AST的阶段都没有什么复杂操作,就不展开介绍了。
最后消耗完所有Token后会检测END Token,如果不是END Token则会报令牌处理未完成的错误。
为了方便查看AST的结构,我们实现一个类似 Python 中 ast.dump() 功能的方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 | class Parser: ... @staticmethod def dump_ast(node, annotate_fields=True, indent=None, level=0): """ 将AST节点转换为字符串表示 Args: node: 要转换的AST节点 annotate_fields: 是否注释字段 indent: 缩进级别 level: 当前节点层级 """ def is_ast_node(obj): return hasattr(obj, '__class__') and hasattr(obj, '__dict__') and isinstance(obj, ASTNode) def format_node(node, level): pad = ' ' * (indent * level) if indent else '' next_pad = ' ' * (indent * (level + 1)) if indent else '' cls_name = node.__class__.__name__ fields = [(k, v) for k, v in node.__dict__.items() if not k.startswith('_')] if not fields: return f"{cls_name}()" # 根据indent决定分隔符 sep = '' if indent is None else '\n' lines = [f"{cls_name}("] for i, (k, v) in enumerate(fields): if isinstance(v, list): if not v: value_str = '[]' else: list_sep = ', ' if indent is None else ',\n' list_pad = '' if indent is None else next_pad + (' ' * indent) value_str = list_sep.join( list_pad + (format_node(item, level + 2) if is_ast_node(item) else repr(item)) for item in v ) if indent is not None: value_str = '[\n' + value_str + f'\n{next_pad}]' else: value_str = '[' + value_str + ']' elif isinstance(v, dict): if not v: value_str = '{}' else: value_str = list_sep.join( list_pad + (format_node(k, level + 2) if is_ast_node(k) else repr(k)) + ': ' + (format_node(v, level + 2) if is_ast_node(v) else repr(v)) for k, v in v.items() ) if indent is not None: value_str = '{\n' + value_str + f'\n{next_pad}'+ '}' else: value_str = '{' + value_str + '}' elif is_ast_node(v): value_str = format_node(v, level + 1) else: value_str = repr(v) if annotate_fields: lines.append(f"{next_pad}{k}={value_str},") else: lines.append(f"{next_pad}{value_str},") lines[-1] = lines[-1].rstrip(',') lines.append(f"{pad})") return sep.join(lines) return format_node(node, level) |
1 | path = ".datas['items'].length['var' != $snum || ("id" >= 3 * 5 && 'age'< @max(10, num2=10 + 5))].n[:15:2]" |
还是以这段语句为例,将其使用 Parser 解析成AST,再使用 dump_ast 格式化输出如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 | SliceNode( type='SliceNode', line=1, column=92, obj=KeyNode( type='KeyNode', line=1, column=91, obj=IndexNode( type='IndexNode', line=1, column=23, obj=KeyNode( type='KeyNode', line=1, column=22, obj=IndexNode( type='IndexNode', line=1, column=7, obj=KeyNode( type='KeyNode', line=1, column=6, obj=KeyNode( type='KeyNode', line=1, column=0, obj=NameNode( type='NameNode', line=1, column=0, name='' ), key='*', is_wildcard=True ), key='datas', is_wildcard=False ), index=StringNode( type='StringNode', line=1, column=14, value='items' ) ), key='length', is_wildcard=False ), index=BinaryOpNode( type='BinaryOpNode', line=1, column=40, left=BinaryOpNode( type='BinaryOpNode', line=1, column=31, left=StringNode( type='StringNode', line=1, column=28, value='var' ), op=Operator(value=!=), right=VarRefNode( type='VarRefNode', line=1, column=33, name=NameNode( type='NameNode', line=1, column=37, name='snum' ) ) ), op=Operator(value=||), right=BinaryOpNode( type='BinaryOpNode', line=1, column=58, left=BinaryOpNode( type='BinaryOpNode', line=1, column=49, left=StringNode( type='StringNode', line=1, column=46, value='id' ), op=Operator(value=>=), right=BinaryOpNode( type='BinaryOpNode', line=1, column=53, left=NumberNode( type='NumberNode', line=1, column=51, value=3 ), op=Operator(value=*), right=NumberNode( type='NumberNode', line=1, column=55, value=5 ) ) ), op=Operator(value=&&), right=BinaryOpNode( type='BinaryOpNode', line=1, column=65, left=StringNode( type='StringNode', line=1, column=64, value='age' ), op=Operator(value=<), right=ScriptCallNode( type='ScriptCallNode', line=1, column=67, module=[], name=NameNode( type='NameNode', line=1, column=70, name='max' ), args=[ NumberNode( type='NumberNode', line=1, column=73, value=10 ) ], kwargs={ NameNode( type='NameNode', line=1, column=79, name='num2' ): BinaryOpNode( type='BinaryOpNode', line=1, column=84, left=NumberNode( type='NumberNode', line=1, column=82, value=10 ), op=Operator(value=+), right=NumberNode( type='NumberNode', line=1, column=86, value=5 ) ) } ) ) ) ) ), key='n', is_wildcard=False ), start=None, end=NumberNode( type='NumberNode', line=1, column=95, value=15 ), step=NumberNode( type='NumberNode', line=1, column=97, value=2 ) ) |
可以看到,该结构与语句的结构相反,语句中最前面的元素(点操作符,会被转换成通配符,上面有提到过)反而在结构的最里层,而结构的最外层 SliceNode 切片节点则是语句的最后一个元素,这样也方便我们在运算时以从后往前的顺序进行解析。如果觉得AST树太长看起来不方便,可以结合结构中的 column(列号)辅助定位。
AST执行
接下来就是最后一步,也是最重要的一步,我们需要执行AST,来实现获取数据的功能。
模块使用访问者模式15来设计,使用这种结构可以更好地让节点的定义和逻辑操作解耦,防止在加入过多功能后节点变得更为臃肿。使用访问者模式,AST节点就只负责进行数据表示,而所有的操作将由访问者来实现。
首先在节点基类中增加通用的访问者入口,使用这种方式无需向每个节点实现访问者入口方法,在访问者调用accept时会自动生成访问方法名。
1 2 3 4 5 6 7 | class ASTNode: ... def accept(self, visitor): method_name = f'visit_{self.__class__.__name__}' method = getattr(visitor, method_name, visitor.generic_visit) return method(self) |
接下来是访问者基类,所有访问者类继承于这个类,不过目前访问者还只有 Evaluator 执行器这一个类,但是如果后续如果要增加类型检测或代码优化等正对于某个节点功能的,集成该类实现对应的访问者即可。
1 2 3 4 5 6 7 8 9 10 | class ASTVisitor: """AST访问者基类""" def generic_visit(self, node): """默认访问方法""" raise NotImplementedError(f"未实现节点类型 {node.__class__.__name__} 的访问方法") def visit(self, node): """访问节点入口方法""" return node.accept(self) |
接下来就是具体的执行器,执行器中每个节点都有一个visit方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | class Evaluator(ASTVisitor): """ 执行器,用于执行AST节点 """ def __init__(self, data): self.data = data self.context = {} def query(self, ast_root: ASTNode): """查询入口方法""" # 标记当前是根查询 self.context['is_root_query'] = True result = self.visit(ast_root) return result |
接下来就分别来介绍这些方法。
NameNode、NumberNode、StringNode
这三种节点作为字面量节点,处理逻辑比较简单,大多数情况直接返回值即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | class Evaluator(ASTVisitor): ... def visit_NameNode(self, node: NameNode): if self.context.get('get_literal', False): # 脚本和变量操作时直接获取字面量名称 self.context['get_literal'] = False return node.name # 如果是根查询,从self.data中获取对应键的值 if self.context.get('is_root_query', False): name = node.name # 取消根查询标记,避免后续节点也被当作根查询 self.context['is_root_query'] = False # 如果是根级别的通配符,返回整个数据 if getattr(node, '_is_root_wildcard', False): return self.data # 从数据中获取对应的值 if isinstance(self.data, dict) and name in self.data: return self.data[name] return None if 'current_item' in self.context: raise NameError(f"名称 '{node.name}' 未定义,位于 {node.line} 行 {node.column} 列") # 非根查询,直接返回节点名称 return node.name def visit_NumberNode(self, node: NumberNode): return node.value def visit_StringNode(self, node: StringNode): """ 访问字符串节点 当在条件过滤上下文中时,尝试从当前项中获取对应键的值 """ value = node.value # 检查是否在条件过滤上下文中 if 'current_item' in self.context: current_item = self.context['current_item'] # 如果当前项是字典且包含该键 if isinstance(current_item, dict) and value in current_item: return current_item[value] # 普通字符串 return value |
不过还是有一些特殊情况需要单独处理的。比如在NameNode中,会先检查上下文中 get_literal 是否为True,当变量和脚本的NameNode调用visit方法时,该值会被置为True,此时只需要直接获取NameNode的字面量值作为参数名或脚本名即可。
如果 get_literal 不是True,则会检测是否是根查询,因为正常情况下,根一定是NameNode16,即便是以点操作符开头,也会在tokenization时被处理成"*.xxx"的格式。在检测到根查询,且查询值为通配符时,就会直接返回整个数据,否则从数据中获取对应key为name的值。
如果不是根查询,首先会检测 self.context 中是否有 current_item,context用于保存上下文,如果遇到方括号的表达式,会将表达式评估的对象(被过滤的对象)保存到context中,在 NameNode 中如果 context 有 current_item,说明该NameNode在方括号中,而目前语法设计中,NameNode不能出现在方括号中17。NumberNode 没有特殊处理,直接返回具体值。StringNone 会先判断是否包含方括号中,如果是则作为键名进行数据访问18,否则直接返回字符串值。
VarRefNode、ScriptCallNode
变量引用和脚本调用都会用到脚本管理器,所以就一起讲了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | class Evaluator(ASTVisitor): ... def visit_VarRefNode(self, node: VarRefNode): self.context['get_literal'] = True var_name = self.visit(node.name) # 首先从脚本管理器中获取 var = script_manager.get(var_name) # 如果脚本管理器中没有获取到,则从数据中获取 if not var: var = self.data.get(var_name) return var def visit_ScriptCallNode(self, node: ScriptCallNode): self.context['get_literal'] = True func_name = self.visit(node.name) module_path = ".".join([self.visit(module) for module in node.module]) if not script_manager.check_script(name=func_name, path=module_path): raise ValueError(f"未定义的函数: {func_name}, 确保函数在运行前已注册") # 求值所有参数 args = [self.visit(arg) for arg in node.args] kwargs = {self.visit(key): self.visit(value) for key, value in node.kwargs.items()} # 调用函数 return script_manager.run(name=func_name, path=module_path, args=args, kwargs=kwargs) |
实际上最开始设想的变量引用功能是可以直接获取到代码上下文中定义的变量,比如在执行语句前定义了 num = 15,然后在语句中通过$num进行调用。后来发现这种方式行不通,python的globals()作用域仅限于单个模块,在其他模块想要获取要么需要通过传参,要么只能通过importlib来动态导入,而动态导入会严重影响性能,所以最后决定的方案是使用脚本管理器来对变量进行管理,要使用某个变量需要先在脚本管理器中进行注册。
不过这种方法有一个缺点,就是使用这种方法跟使用 path = f"@func(1, {var})" 这种 f-string 没区别了...所以现在这个变量功能似乎没有什么太大的用处,后续如果想到更好的方法再进行优化吧。
在执行 VarRefNode 和 ScriptCallNode 时都要先取消 is_root_query 标记,否则当变量或脚本作为根节点运行时,在处理 NameNode 时会出问题。
变量节点首先会通过脚本管理器的get方法尝试获取变量,如果脚本管理器中没有获取到变量值(包括变量值为None的情况),就会将$作为整个数据根19,并且可以通过语句进行索引,比如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | from dictquerier import query_json, script_manager @script_manager.register() def echo(content): print(f"echo传入的值: {content}") return content data = { "items": { "inner": { "keyname": ["data", "data2"], "data": { "key": "value" }, "data2": { "key": "value2" } }, } } path = "items.inner[@echo($items[inner].keyname[1])].key" result = query_json(data, path) print(f"最终结果: {result}") # 输出: # echo传入的值: data2 # 最终结果: value2 |
接下来是脚本调用,同样也需要先取消根查询标记。在进行调用前,首先会对 ScriptCallNode 中的函数名称进行处理,使用点对所有module进行连接,然后调用脚本管理器的check_script检查是否是可调用脚本,如果是可调用脚本,则将所有的普通参数处理成list,kwargs参数处理成dict,然后调用脚本管理器的run方法运行脚本。
脚本管理器
变量的定义存取和脚本的调用都依赖于脚本管理器进行。先说变量功能,目前来说变量暂时还只是对数据进行一个存储,没有任何逻辑处理,具体实现的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | class ScriptManager: def __init__(self): self.scripts = {} self.variables = {} # 缓存数据 self._module_cache = {} self._function_cache = {} # 调用状态统计 self._stats = { 'hits': 0, 'misses': 0, 'total_calls': 0, } ... def define(self, var_name, var_value): self.variables[var_name] = var_value def get(self, var_name): return self.variables.get(var_name) |
脚本管理器中比较主要的是脚本管理部分(废话了),脚本分为注册、卸载、检查、调用三个主要操作。先说注册,使用register装饰器对函数进行标记以注册,注册的脚本会被以键值对的形式存到脚本管理器的 self.scripts 中,其中键是脚本名称,值是对应方法。注册功能的实现非常简单:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | class ScriptManager: ... def register(self, name: str = None): """ 注册脚本 Args: name (str, optional): 自定义脚本调用名,可选 Returns: """ def decorator(func): key = name or func.__name__ self.scripts[key] = func return func return decorator |
对应的是卸载功能:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 | class ScriptManager: ... def unregister(self, name: str) -> bool: """ 卸载已注册的脚本 Args: name (str): 要卸载的脚本名称 Returns: bool: 卸载是否成功 """ if name in self.scripts: # 从scripts字典中移除 del self.scripts[name] # 清除相关缓存 self.clear_specific_cache(name) return True return False def clear_specific_cache(self, name: str, path: str = None): """ 清理特定脚本的缓存 Args: name (str): 脚本名 path (str, optional): 模块路径 """ cache_key = self._get_cache_key(name, path) if cache_key in self._function_cache: del self._function_cache[cache_key] # 如果有path,尝试清理模块缓存 if path: parts = path.split('.') module_path = parts[0] # 只清理顶级模块 if module_path in self._module_cache: del self._module_cache[module_path] def _get_cache_key(self, name: str, path: str = None) -> str: """生成缓存键""" return f"{path}:{name}" if path else name |
在卸载的同时会清除掉对应的已缓存的方法。
目前脚本管理器还只支持同步函数的注册和调用,对于需要进行一些IO请求或一些耗时较长的函数来说不太友好,后续可以尝试引入异步函数注册和调用的方法,需要重新设计一下异步函数的查询调用语法。
接下来就是脚本的检查和调用部分,因为调用前会先执行检查,所以这两部分就一起讲了。除了自行注册的脚本外,脚本管理器还支持调用 Python 自带的模块和内置方法,具体调用流程是:
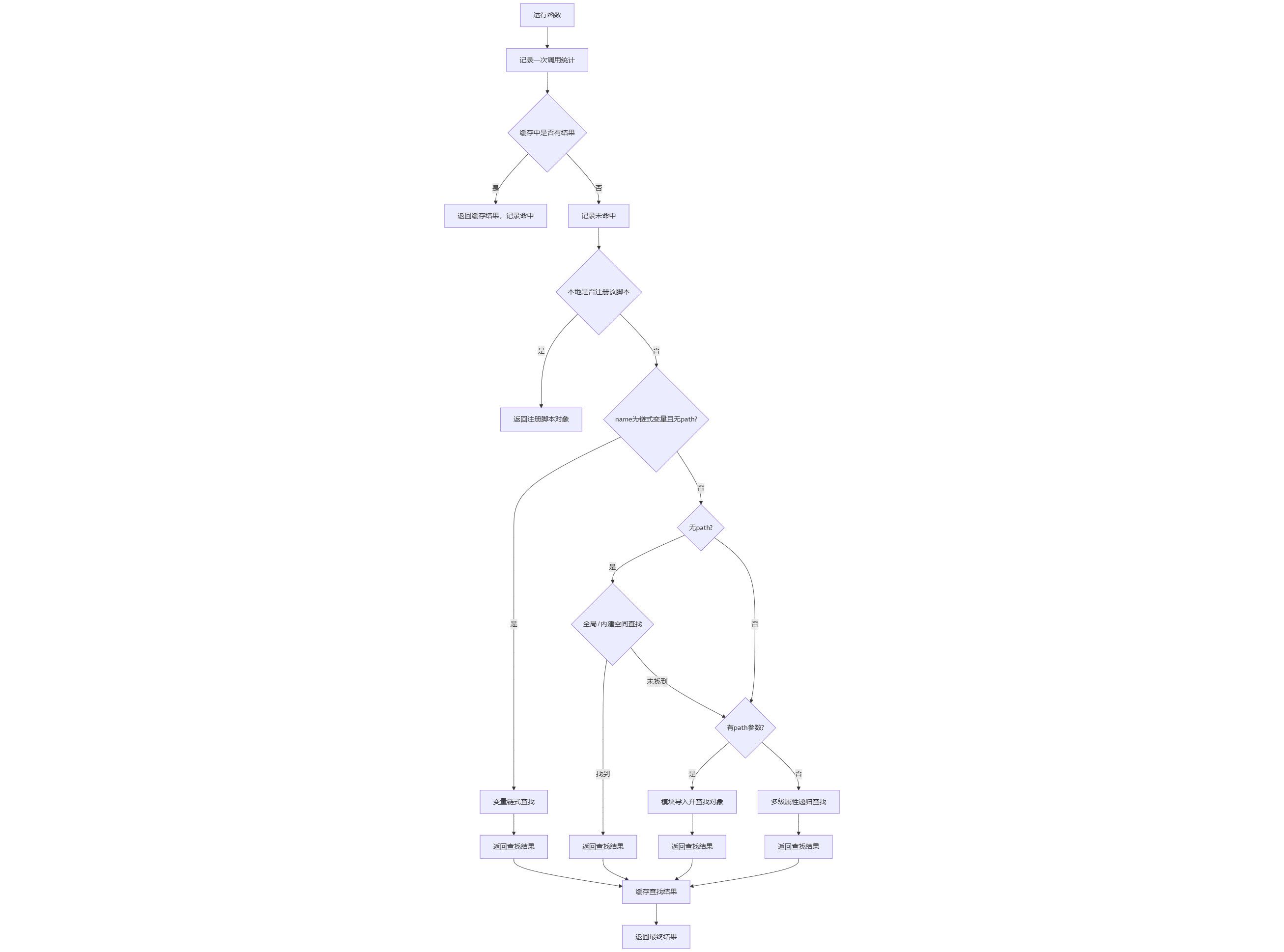
运行脚本和检查脚本共用同一套逻辑,区别是运行脚本会在取得脚本后运行,这一部分代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 | class ScriptManager: ... def _record_call(self): """记录调用统计""" self._stats['total_calls'] += 1 def _record_hit(self): """记录缓存命中""" self._stats['hits'] += 1 def _record_miss(self): """记录缓存未命中""" self._stats['misses'] += 1 def check_script(self, name: str, path: str = None) -> bool: """ 检查脚本是否存在或可调用 Args: name (str): 脚本名 path (str): 模块路径,可选 Returns: bool: 是否存在或可调用 """ # 直接使用_get_function的结果 _, is_callable = self._get_function(name, path) return is_callable def _get_function(self, name: str, path: str = None) -> Tuple[Optional[Callable], bool]: """ 获取脚本并缓存结果 Args: name: 脚本名 path: 模块路径,可选 Returns: (脚本对象, 是否可调用) """ self._record_call() cache_key = self._get_cache_key(name, path) if cache_key in self._function_cache: self._record_hit() return self._function_cache[cache_key] self._record_miss() result = (None, False) # 已注册的脚本 if name in self.scripts: result = (self.scripts[name], True) # 变量属性访问 elif '.' in name and not path: var_parts = name.split('.') var_name = var_parts[0] if var_name in self.variables: try: obj = self.variables[var_name] for part in var_parts[1:]: obj = getattr(obj, part) result = (obj, callable(obj)) except (AttributeError, TypeError): pass # 检查全局脚本 elif not path: import __main__ main_globals = vars(__main__) if name in main_globals and callable(main_globals[name]): result = (main_globals[name], True) else: import builtins if hasattr(builtins, name): builtin_obj = getattr(builtins, name) if callable(builtin_obj): result = (builtin_obj, True) # 多级模块导入和属性访问 if result == (None, False): # 如果前面的尝试都失败了 try: if path: # 处理多级路径 if '.' in path: try: path_parts = path.split('.') module = self._import_module(path_parts[0]) obj = module for part in path_parts[1:]: obj = getattr(obj, part) if hasattr(obj, name): func = getattr(obj, name) if callable(func): result = (func, True) except (ImportError, AttributeError, ValueError): pass else: # 单级路径,直接导入模块 try: module = self._import_module(path) if hasattr(module, name): func = getattr(module, name) if callable(func): result = (func, True) except (ImportError, AttributeError, ValueError): pass else: # 处理name是多级路径的情况 full_path = name parts = full_path.split('.') if len(parts) > 1: module_path = parts[0] attr_chain = parts[1:] try: module = self._import_module(module_path) obj = module for attr in attr_chain: obj = getattr(obj, attr) result = (obj, callable(obj)) except (ImportError, AttributeError, ValueError): for i in range(1, len(parts)): try: potential_module = '.'.join(parts[:i]) potential_attrs = parts[i:] module = self._import_module(potential_module) obj = module for attr in potential_attrs: obj = getattr(obj, attr) if callable(obj): result = (obj, True) break except (ImportError, AttributeError, ValueError): continue except Exception: pass # 保存到缓存 self._function_cache[cache_key] = result return result def run(self, name: str, path: str = None, args=None, kwargs=None): """ 调用脚本 Args: name (str): 脚本名 path (str): 模块路径,可选 args: 位置参数列表 kwargs: 关键字参数字典 """ if args is None: args = [] if kwargs is None: kwargs = {} # 通过缓存获取脚本 func, is_callable = self._get_function(name, path) if func and is_callable: return func(*args, **kwargs) if path: raise UnknowScript(f"'{path}.{name}' 不存在或不是可调用对象") elif '.' in name: raise UnknowScript(f"'{name}' 不存在或不是可调用对象") else: raise UnknowScript(f"脚本 '{name}' 未找到或不可调用") def _import_module(self, module_path: str) -> Any: """ 导入模块并缓存结果 Args: module_path: 模块路径 Returns: 导入的模块 """ if module_path in self._module_cache: self._record_hit() return self._module_cache[module_path] try: self._record_miss() module = importlib.import_module(module_path) self._module_cache[module_path] = module return module except ImportError as e: raise ValueError(f"无法导入模块 '{module_path}': {e}") |
如果缓存未命中,且不是注册脚本,脚本管理器就会尝试通过动态导入来尝试获取可执行脚本,这一步开销比较大,如果每一次都尝试使用 importlib.import_module 进行导入,则会严重影响执行效率,更何况该模块的使用场景决定了其必然会大量重复的调用。所以模块会对使用过一次的函数进行缓存,防止二次导入,极大的增加了重复调用的效率。关于缓存功能,脚本管理器还包括一个调用次数统计,暂时没有什么具体的作用,主要用于调试。
除了从已注册脚本和导入模块脚本获取可执行脚本外,管理器还会尝试分析path。虽然path20的格式都是 xxx.xxx.funcname 这种,但实际上这些路径的类型可能是有区别的:
- 模块.函数:比如 random.randint,其中 random 是模块名称,randint 是模块函数。
- 模块.类.方法:比如 datetime.datetime.now,其中 datetime 是模块名称,第二个 datetime 是类名(datetime模块中的datetime类),最后的 now 是 datetime 类的一个类方法。
- 模块.子模块.方法 或 模块.子模块.类.方法:这个我懒得找例子了,但是基本概念和上面一样,只是中间多一级21
- 基于上述结构,但最后不是方法,而是枚举或变量的情况:这种情况暂时没有做相关功能的适配。
在上述情况中,由于模块和类的导入方法不同,导致在执行动态导入时不能完全按照模块来处理。所以管理器只会对顶级模块使用 importlib.import_module 进行导入,后续的子模块和类将使用 getattr 方法进行判断和导入。
获取到对应的脚本后,直接传入参数运行。
BinaryOpNode
接下来回到执行器部分,继续介绍节点执行器的二元运算节点执行器。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 | class Evaluator(ASTVisitor): ... def visit_BinaryOpNode(self, node: BinaryOpNode): """ 处理二元操作符节点 支持: 1. 条件过滤 (>, <, ==, !=, >=, <=) 2. 逻辑运算 (&&, ||) 3. 四则运算 (+, -, *, /) """ # 对于短路操作符,先评估左操作数 left = self.visit(node.left) # 短路求值 if node.op == Operator.LOGICAL_AND and not left: return False if node.op == Operator.LOGICAL_OR and left: return True # 对于非短路操作符或需要继续计算的短路操作符,计算右操作数 right = self.visit(node.right) # 逻辑操作符 if node.op == Operator.LOGICAL_AND: return left and right elif node.op == Operator.LOGICAL_OR: return left or right # 比较操作符 elif node.op == Operator.EQUAL: return left == right elif node.op == Operator.NOT_EQUAL: return left != right elif node.op == Operator.GREATER_THAN: return left > right elif node.op == Operator.LESS_THAN: return left < right elif node.op == Operator.GREATER_EQUAL: return left >= right elif node.op == Operator.LESS_EQUAL: return left <= right # 算术操作符 elif node.op == Operator.PLUS: return left + right elif node.op == Operator.MINUS: return left - right elif node.op == Operator.MULTIPLY: return left * right elif node.op == Operator.DIVIDE: # 防止除零错误 if right == 0: raise ZeroDivisionError("除数不能为零") return left / right # 不支持的操作符 else: raise UnknownOperator(f"不支持的操作符: {node.op}") |
所有的条件运算、逻辑运算和基本四则运算都属于二元运算,用比较抽象的话22来说就是:接受两个来自集合 S 的元素作为输入,并输出一个仍属于该集合 S 的元素的运算就是二元运算。
在 BinaryOpNode 中,首先会对左操作数节点进行visit操作,以获得左操作数值,这一步是为了便于短路操作符的短路求值处理。当操作符为 && 和 || 时,首先判断左操作数,在 && (取并集)的情况下,如果左操作符不满足条件,则直接返回False;在 || (取交集)的情况下,如果满足条件则直接返回True。
如果上述条件不满足,则继续计算右操作数,最后将得到的左操作数结果和右操作数结果按照对应操作符进行计算,并返回计算结果。
KeyNode
KeyNode主要用于通过键获取对应数据,其返回的值是具体的数据对象,其参数类型应该是字符串字面量。KeyNode来源于点操作符。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | class Evaluator(ASTVisitor): ... def visit_KeyNode(self, node: KeyNode): obj = self.visit(node.obj) key = node.key if obj is None: return None # 处理通配符 obj.* if node.is_wildcard: # 列表对象 if isinstance(obj, list): return obj # 字典 if isinstance(obj, dict): return obj return None # 对列表中的每个元素获取同名键 if isinstance(obj, list): result = [] for item in obj: if isinstance(item, dict) and key in item: result.append(item[key]) elif hasattr(item, key): result.append(getattr(item, key)) return result if result else None # 处理字典 if isinstance(obj, dict): return obj.get(key) # 处理对象属性 if hasattr(obj, key): return getattr(obj, key) return None |
在处理具体键前会先判断是否是通配符 datas.* 的形式,如果是通配符则直接照原样返回所有数据。
接下来根据当前数据类型分别进行处理。如果是当前是列表,则遍历列表中每个元素,并获取列表中每个元素对应键的值,然后组成一个新的列表返回;如果是字典,则直接取对应键的值;最后还会通过 hasattr 判断一下是否是有属性的对象,如果有这个属性,则返回属性值。
IndexNode
IndexNode主要功能与KeyNode类似,但该节点设计的数据类型更广泛,来源也有所不同。IndexNode的返回值也是一个具体的数据对象,但其值可以是任意字面量或表达式。IndexNode来源于方括号语法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 | class Evaluator(ASTVisitor): ... def visit_IndexNode(self, node: IndexNode): obj = self.visit(node.obj) if obj is None: return None # 检查是否是通配符索引 (index 是 StringNode 且值为 *) if isinstance(node.index, StringNode) and node.index.value == '*': # 列表 if isinstance(obj, list): return obj # 字典 elif isinstance(obj, dict): return obj return None # 检查是否是条件过滤 (index 是 BinaryOpNode) if isinstance(obj, list) and isinstance(node.index, BinaryOpNode): result = [] # 对列表中的每个元素应用条件 for item in obj: # 保存旧上下文 old_context = self.context.copy() # 设置当前项为上下文 self.context['current_item'] = item try: # 计算条件表达式 condition_result = self.visit(node.index) # 如果条件为真,将项添加到结果中 if condition_result: result.append(item) finally: # 恢复上下文 self.context = old_context return result # 处理字符串索引作为键访问的特殊情况,如obj["key"] if isinstance(node.index, StringNode): key = node.index.value # 对于字典,直接按键访问 if isinstance(obj, dict): return obj.get(key) # 对于列表中的字典元素,获取指定键 elif isinstance(obj, list): result = [] for item in obj: if isinstance(item, dict) and key in item: result.append(item[key]) elif hasattr(item, key): result.append(getattr(item, key)) return result if result else None # 对于对象,尝试访问属性 elif hasattr(obj, key): return getattr(obj, key) return None # 普通索引访问 index = self.visit(node.index) # 处理列表或元组 if isinstance(obj, (list, tuple)): if isinstance(index, int) and 0 <= index < len(obj): return obj[index] return None # 处理字典 if isinstance(obj, dict): return obj.get(index) return None |
IndexNode也会优先对通配符进行处理,判断是否为 datas['*'] 的格式,如果是通配符则直接照原样返回所有数据,这一点与KeyNode处理方式相同。
接下来会检查方括号内是否是二元操作表达式,并且数据是列表类型。如果满足要求,则会遍历list中的每条数据,并且调用二元操作的visit方法获取二元操作的值,如果为True则将数据添加到结果列表以组成新的结果返回。
接下来就是普通的字符串字面量索引查询键、数字索引查询列表和元组的操作,这一点没什么好说的。
SliceNode
最后是切片节点SliceNode,专门用于处理形如 list[2:3] 的切片语法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | class Evaluator(ASTVisitor): ... def visit_SliceNode(self, node: SliceNode): obj = self.visit(node.obj) if obj is None: return None # 检查切片值是否合法 start = self.visit(node.start) if node.start else None end = self.visit(node.end) if node.end else None step = self.visit(node.step) if node.step else None if start and not isinstance(start, int): raise ValueError("切片起始值必须为整数") if end and not isinstance(end, int): raise ValueError("切片结束值必须为整数") if step and not isinstance(step, int): raise ValueError("切片步长必须为整数") if step == 0: raise ValueError("切片步长不能为0") # 暂定,后续可能增加一些特殊切片处理,比如numpy中的多维切片 return obj[start:end:step] |
这个节点主要的操作逻辑都在语法解析部分了,执行部分相对比较简单,是直接获取到start、end、step参数,然后使用Python的切片语法 obj[start:end:step] 直接返回结果。
不过正如注释中所述,后续我打算加入更复杂的切片索引语法支持,比如numpy中形如 list[0:2, 1:3] 的多维切片。
其余功能模块
以上就是执行器对于每个不同类型AST节点的处理方式,结合词法分析、语法分析、AST执行器,即可构成一套完整的数据查询流程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | from dictquerier.executor.evaluator import Evaluator from dictquerier.tokenizer.lexer import Lexer from dictquerier.syntax_tree.parser import Parser from dictquerier import script_manager @script_manager.register() def echo(arg): print(f"the arg is {arg}") return arg data = { "items": [ {"type": "B", "name": "value1", "age": 10}, {"type": "A", "name": "value2", "age": 20}, {"type": "B", "name": "value3", "age": 30}, {"type": "A", "name": "value4", "age": 40}, {"type": "B", "name": "value5", "age": 50}, ], "list": [i for i in range(50,100)] } script_manager.define("a", 20) path = "items['type' == 'A' && 'age' > @echo($a)].name" # 词法分析 lexer = Lexer(path) tokens = list(lexer.tokenize()) # 语法分析 parser = Parser(tokens) ast_root = parser.parse() # 执行AST evaluator = Evaluator(data) result = evaluator.query(ast_root) print(result) |
上面这段代码中,由于短路操作,会先判断 'type' == 'A' 满足条件后才会继续判断 'age' > @echo($a),并且五条数据中,两条满足 'type' == 'A' 的都会执行 @echo($a),所以该脚本会被调用两次,最终输出应该如下:
1 2 3 | the arg is 20 the arg is 20 ['value4'] |
将这些流程封装成一个可以直接调用的函数,基本上就完成了整个模块核心功能的开发:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | def query_json( data: Union[Dict, List], path: str, no_path_exception: bool = False, ) -> Any: r"""查询json数据 Args: data (Union[Dict, List]): 需要查询的json结构 path (str): 查询路径语句 no_path_exception (bool, optional): 关闭报错,该项设置为True时,查询出错不会产生报错,而是返回空列表[]. Defaults to False. Returns: Any: 查询结果 """ try: # 词法分析 lexer = Lexer(path) tokens = list(lexer.tokenize()) # 语法分析 parser = Parser(tokens) ast_root = parser.parse() # 执行查询 evaluator = Evaluator(data) result = evaluator.query(ast_root) return result except Exception as e: if no_path_exception: return [] raise e |
除此之外,我还让AI帮我生成了一些可以直接在命令行中使用的命令参数,安装dictquerier后就可以直接在命令行中通过以下命令快速调用查询:
1 2 3 4 5 6 7 8 9 10 11 | # 从文件查询 dictquerier -f data.json -p "users[*].name" # 直接使用JSON字符串 dictquerier -i '{"users":[{"id":1,"name":"张三"}]}' -p "users[0].name" # 保存结果到文件 dictquerier -f data.json -p "users['id'>1]" -o result.json # 使用紧凑输出格式 dictquerier -f data.json -p "users[*].name" -c |
具体的代码就不多说了,实现起来很简单。
小结
dictquerier 经过多次改版,最终变成现在这个样子。文章的核心并非仅仅是JSON查询功能本身,而是深入剖析了如何设计和实现一个小型查询语言的解析器。我们从最初的字符串处理和简易状态机方案出发,渐渐发现其在可维护性和扩展性上的局限。随着需求的增加,例如列表索引、切片以及条件过滤,原有的方案变得难以应对,原有的实现方式逐渐复杂且不可扩展和维护,直到重构以后变成现在拥有一整套词法分析和处理的流程。实际上现在的代码除了实现同一个目标23外,感觉已经改得跟最初的版本都没啥关系了。
同时由于我在写这篇文章的时候,同时也在不断对代码增加新功能以及debug,所以文章中的内容和实际代码有可能出现少许差异,最终以代码为准即可。
最开始我是想把这个模块命名为 jsonquerier,不过后来为了和使用json path语句的查询工具区分开,改名成 dictquerier 了。但是众所周知,python的dict中一切可以hash的、不可变的数据类型24都可以作为字典键名,但是目前该模块还只支持查询字符串作为键的键名,所以后续的努力方向之一就是增加更多数据类型的字典键支持了。
虽然这个工具可能还不足以在实际工作环境中稳定运行,但是却是一次很重要的学习经验,从这个切入点触发,可以让我们揭开编程语言语句解析器设计的一角。不过本文介绍到的词法分析、语法分析和AST等,都是编程语言解析和编译中最最基础的概念,但实际上要实现一个编译器远不止这么简单,后续有机会我可能会尝试实现一个简单的解释性语言执行器。
本文的全部代码可以在我的GitHub仓库中找到。
- 后续会提到,代码经历过一次彻底的重构,其处理逻辑发生了根本性的变化。 ↩︎
- 目前来说,所谓的脚本其实就是函数,因为目前还没有实现其他脚本语句(比如判断、循环等)的解析,只实现了函数调用。 ↩︎
- 作为一个有限状态机,其状态集合为不同条件下需要处理的不同输入;输入字符集就是语句字符串的字符;状态转移函数就是具体的逻辑分支(在最初版本中也就是点操作符和元素的分支);当前状态变量是处理过程中的存储变量,比如buffer;接受/拒绝机制就是判断语句或元素是否合法; ↩︎
- 根节点需要分类讨论,如果其作为叶子节点,则也应该是比较表达式,否则应该是逻辑表达式。 ↩︎
- 这个模块的语句分析和语言(比如Python)解释器的源代码分析从原理上来说相似,但不完全一样。 ↩︎
- 结尾在开头之前,从逻辑上来说永远不会被匹配。 ↩︎
- 因为目前查询语句设计只有一行,所以实际上行号始终为1,但留出行号也方便后续扩展更复杂的语法支持。 ↩︎
- 目前没有对空格严格要求的语法,但不排除后续会增加部分语法中对空格有要求,但现在引入空格没有必要,索性直接跳过了。字符串中的空格不会受到影响。 ↩︎
- 也不算特别早,就是 Python 3.9 以前。 ↩︎
- 一种自顶向下,基于预测分析表的解析器。其中第一个L表示左到右(Left-to-right);第二个L表示最左推导(leftmost derivation);1表示“一个符号”的 lookahead 来决定使用哪条语法规则。 ↩︎
- Python 解释器中实现的语法解析工具叫pegen. ↩︎
- 使用递归下降解析器实现 PEG 需要一些特殊写法,比如手动实现回溯、lookahead、贪婪匹配等功能。 ↩︎
- 递归本身指的是自己调用自己,这里指的是函数中调用函数,但实际上会有回调,比如A调用B,B在某种情况下又会调用A,所以也算是递归了。 ↩︎
- 形如 random.randint() 的格式。 ↩︎
- 24种常用的基本设计模式之一,大多数解释器都是使用访问者模式进行代码处理的。 ↩︎
- 这里算是一个设计失误,因为路径中间是可以以字符串作为路径的,比如:"path.'to'.data" 这是合法且可以正确运行的查询语句,使用这种方法可以处理一些特殊字符(比如键名中带有点字符,甚至键名就是一个点,即"path.'.'.data" 或 "path.'key.01'.data",其中key.01为一个键),但根不能使用这种语法,比如 "'path'.to.data" 这种写法会返回None。 ↩︎
- 如果是变量或函数,会被转成对应的 VarRefNode 和 ScriptCallNode,所以目前的语法方括号中不可能出现 NameNode,如果出现了就应该直接报错。 ↩︎
- 也就是 dict["key"] 这种访问模式。 ↩︎
- 这里的作用有点类似于Json Path中的$,但我感觉这里功能设计得不太好,可能需要重新设计一下。 ↩︎
- 这里所谓的path指的是导入模块函数名前面的部分,比如 datetime.datetime.now(),其函数名为 now,path 为 datetime.datetime,不管其究竟是模块还是类。 ↩︎
- 或者多几级,比较 python 对包的嵌套深度没有一个明确的限制。 ↩︎
- 来自二元运算(Binary operation)的定义。 ↩︎
- 解决在处理层层嵌套、结构混乱的JSON数据时,通过大量 .get() 调用导致代码可读性和可维护性下降的问题。 ↩︎
- 详见Python文档的 Built-in Types 的 Immutable Sequence Types 一节。 ↩︎