




前端时间写了一篇blog,讲了一下如何使用frida工具来绕过安卓APP的ssl固定,并使用工具进行抓包,以找到所需要的接口。但实际上之前的步骤基本上没有涉及到什么逆向分析相关的内容,frida的玩法还有很多,这篇文章我们会了解到如何使用这个工具对APP进行进一步的分析,来达到我们需要的采集数据的目的。
注意:
本文有小部分内容由AI辅助创作,部分内容的真实性存疑,请自行判断。
本文会使用到一些方法绕过GFW,请在使用互联网时遵守当地的相关法律法规。
本文涉及到软件逆向分析,请注意在实践过程中的法律问题。
根据《中华人民共和国刑法》第286条:
违反国家规定,对计算机信息系统功能进行删除、修改、增加、干扰,造成计算机信息系统不能正常运行,后果严重的,处5年以下有期徒刑或者拘役;后果特别严重的,处5年以上有期徒刑。
违反国家规定,对计算机信息系统中存储、处理或者传输的数据和应用程序进行删除、修改、增加的操作,后果严重的,依照前款的规定处罚。
故意制作、传播计算机病毒等破坏性程序,影响计算机系统正常运行,后果严重的,依照第1款的规定处罚。
如果你已经忘了之前的内容,可以先去复习一下:
书接上回
在之前的逆向分析工作当中,我们提到了有关请求中authorization头的问题1,当时只是说到,在X的开发者文档中有auth头的算法,我们可以直接通过这个算法来构造auth头。然而在实际的逆向工作中,很多时候官方并不会给出这些参数的算法,我们只能靠自己去寻找其构造方法,今天我们主要的目的就是通过反编译等手段,在不依赖官方文档的情况下,尝试找到authorization头的构造方法。
需要提前了解的信息
注意: 下面所说的x86平台/x86平台软件皆指Windows NT或linux软件(不包括基于Linux内核开发的AOSP),并非所有x86平台的软件(因为安卓也有x86版本)我将其称为x86只是为了方便,明白其意思就行。
不同平台软件的编译流程
在对安卓软件进行逆向分析之前,我们需要先了解其软件结构,以及其结构上与普通x86平台(Windows NT或linux)软件结构的差异。
x86软件编译流程
我们知道,一个软件从(高级编译型语言)源代码到最终的可执行程序(exe或elf)分为以下几步:
- 编写源代码: 使用C/C++或其他类似的高级编程语言来编写软件运行的逻辑的代码。
- 预处理: 完成代码编写后,通过编译器编译代码,编译器首先会对源代码进行预处理工作,比如处理C语言中的包引入或宏定义(#include和#define)等。这一步会将源代码转换成预处理代码,并继续由编译器进行下一步处理。
- 编译: 编译器获得预处理的代码后,会开始进行编译工作,这一步中编译器会将经过预处理的高级编程语言代码转换成相对来说较为底层的汇编代码。这一过程包含词法分析、代码优化、代码翻译等。
- 汇编编译: 编译得到的汇编语言由汇编器进一步翻译成可由CPU识别的机器码,最后生成得到的文件叫目标文件2
- 链接: 链接分为静态链接和动态链接,其中静态链接是将上一步得到的多个目标文件和静态库合并到一起;动态链接指的是在软件运行时加载动态库3。除此之外,链接程序还可以分配可执行文件的堆栈、代码段位置等。这一步最终得到的是可执行文件4。
这里只是简单地对流程进行了描述,有关更加详细的编译流程,以及每个过程中编译器都干了些什么,我有可能会在操作系统开发系列文章中写到(现在还没有,以后不知道会不会补上)。
安卓软件编译流程
因为本文主要研究的是安卓软件的逆向分析,所以这一部分相对来说更加重要一些,x86平台软件的编译流程只需要稍作了解即可,因为安卓软件和x86平台的编译过程几乎完全不同,步骤上相对来说也会更多一些。
安卓软件大多由Java或Kotlin语言开发,这两种语言最后都需要编译成Dalvik可执行格式,安卓系统的软件运行机制,决定了安卓软件结构注定与ELF或PE不同。
安卓软件的编译流程如下:
- 编写源代码: 与x86软件相同,安卓软件也需要编写源代码(废话),但是安卓大多使用Java语言或Kotlin(从某种意义上来说算是Java的超集)。不过在需要高性能计算,或对底层硬件进行操作时,也会直接使用C/C++进行开发,C/C++通过JNI(Java Native Interface)来调用,使用C/C++开发需要用到NDK(Native Development Kit)。
- 代码编译: 对于Java或者Kotlin代码来说,编译器会将源代码编译成JVM的字节码,并保存到文件中,这些文件的后缀一般是.class;对于C或C++代码来说,编译器会使用NDK中的交叉编译工具链,并将源代码编译成对应架构的机器码,其中的步骤与上面提到的x86软件编译流程类似,但不完全相同,最后得到的是动态库(.so)文件,这些文件会被安卓程序运行时动态调用。
- 转换字节码: 这一步会通过dx或d8工具将字节码转换成Dalvik格式,该格式的文件后缀名通常为.dex。该格式的字节码可以在Dalvik虚拟机或ART(安卓运行时 Android Run-time)运行。
- 资源打包: 要生成可以用于安装的apk文件(或xapk文件),还需要将资源文件(图片、文本字符串以及其他资源文件)和XML布局文件进行打包,这一步编译器会将资源的资源id生成到R.java文件中,这个文件最终会被编译到classes.dex中(字节码文件),最后将所有的字节码和资源打包到apk文件中。
- 签名与对齐: 经过上面四个步骤,就已经可以得到最终的apk文件了,但是实际上还需要对apk进行签名,这一步是防止apk被恶意修改,以及保证apk的完整性;对apk进行对齐操作,可以提高apk的运行效率。
经过上述步骤得到的apk文件,可以被安装到安卓系统中并运行。
在软件第一次运行时,还会进行一次编译,安卓运行时在首次运行软件时,会将.dex字节码进行AOT(Ahead-of-Time)编译,转换为本地机器码,存储为.oat文件,以提高运行性能。所以有一部分软件,刚装上启动会比较慢,但后续再使用就会变快。
与x86软件直接运行于CPU不同,安卓软件一般运行于虚拟机之上,或经过AOT编译的环境中。从这一点原理上来看,安卓软件的效率无法达到100%。
安卓软件的基本结构
安卓软件从结构上来说,与x86软件也有较大不同。
应用框架和组件化设计
安卓应用遵循特定的生命周期框架以及组件化设计,比如Activity、Service、BroadcastReceiver、ContentProvider等组件。其中,一个Activity就是一个单独的屏幕或用户界面(UI)。它负责与用户进行交互,展示界面元素,并响应用户的操作。每个Activity都有自己的生命周期(创建、启动、暂停、销毁等),一个app可以包含多个Activity,不同的Activity之间通过Intent进行导航;Service是一种后台执行长时间运行操作的组件,其只负责任务执行,Service可以在应用退出(到后台)后保持运行,确保后台任务不会中断,比较常见的例子是音乐播放器,不会因为退出app而中断音乐。BroadcastReceiver是用于接收和响应系统或应用程序发送的广播消息的组件,app通过该组件接收系统发送的广播消息(比如设备启动、网络状态变化、电量低等);ContentProvider是用于在不同应用程序之间共享数据的组件。它定义了一套标准的接口,允许其他应用按照安全的方式访问和修改数据。ContentProvider管理的数据通常存储在文件、数据库或其他持久化存储中。
上面四个是在安卓开发中比较常用的四个组件,其余的可以在Google官方的Android开发文档中查到。
而在x86软件方面,就没有严格的生命周期规定,各软件遵循自己的生命周期管理方式,这一点不同软件根据其开发思路和运行的系统平台可能有所不同。
软件资源管理
在资源管理方面,安卓软件高度依赖资源文件,软件使用XML进行布局,其描述了界面组件如何在屏幕上排列、显示和交互。为了对不同端设备分辨率进行匹配,安卓可以同时保存多套分辨率的布局,并根据设备实际情况进行调整。
而x86软件则没有固定的资源管理要求,有可能通过文件系统管理资源,也有可能直接通过代码来生成用户界面,或者使用类似QT这种第三方的用户界面库。总之,x86平台没有一套标准的资源和界面管理规定。
用户操作与运行机制
除了部分辅助类软件外,安卓软件大多数都依赖于用户界面,用户通过界面进行操作,而不像x86平台,除了应用程序界面外,软件还可能以命令行或后台服务等形式存在和运行。
在软件运行方面,安卓软件运行在沙盒环境中,权限管理严格,各APP相互相对独立,应用间共享依赖于Intent机制,对设备权限也需要提前通过AndroidManifest.xml向安卓系统进行权限申请;而x86软件则相对更自由,没有太多的强制性的标准规则,也可以进行更底层的操作。
虽然安卓系统也支持PC或IOT设备,但安卓软件的各方面框架设计更加偏向于类似手机或平板类的移动设备。
安卓逆向分析工具
我们可以使用逆向分析工具,对安卓apk进行解包,反编译和动态调试。
每个安卓apk包实际上就是一个ZIP文件,如下图所示,文件头为504B(PK,ZIP文件的标准文件头):
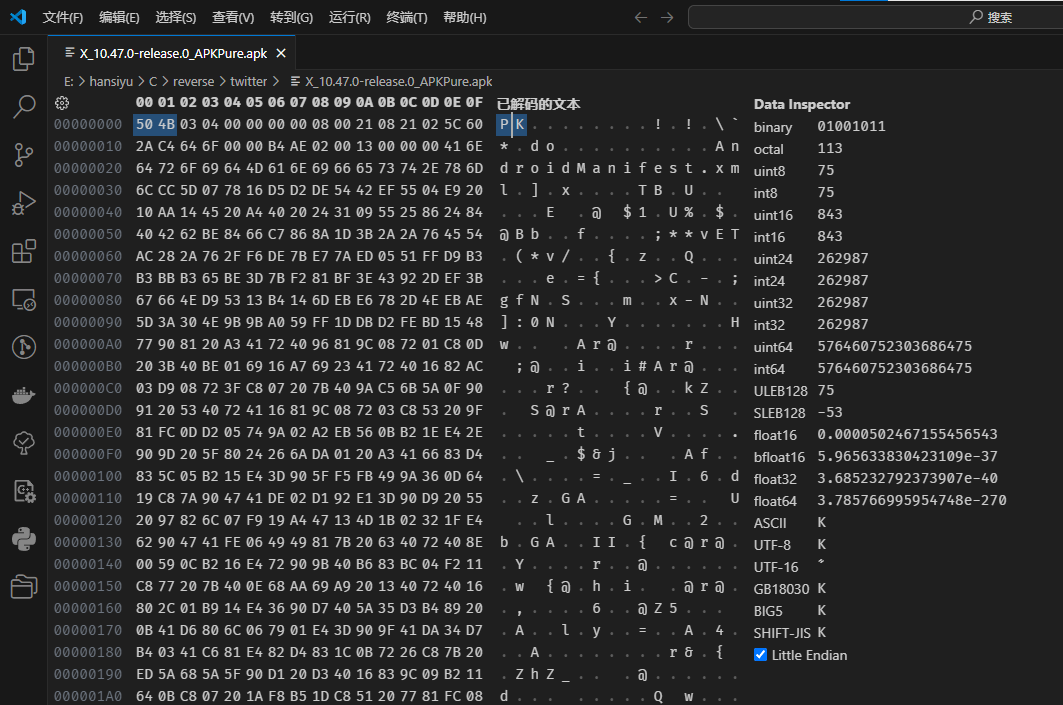
所以在逆向分析时会先对apk进行解包,并获取其中的dex文件和资源文件。
在获取到dex文件后,逆向分析工具会对其进行反编译,将机器码反编译成汇编代码,部分逆向分析工具还支持将汇编代码翻译成Java伪代码,这一步我们在后续实际操作中还会详细介绍到。
除此之外,部分逆向分析工具还可以对资源进行提取和修改、进行动态分析和调试、以及对代码进行注入和修改等。
除了之前已经提到的frida以外,常用的逆向分析工具是APKTool,该工具可以对apk进行反编译,在修改代码后回编成apk并签名发布。但是本文不涉及代码的修改,只需要分析代码,所以用不上这个工具。
本文会主要使用的JEB,该工具也主要用于对安卓软件的反编译和代码分析,并且也有动态断点调试功能。该软件也支持一些脚本和插件类的开发,但是本文也用不上。这个软件的Pro版是付费的,但是网上可以找到“学习版本”,当然,也可以使用免费的社区版。
了解了这些前置信息后,我们可以尝试对X进行逆向分析。
着手开始逆向分析
环境准备
按照之前文章的步骤,准备好firda和模拟器环境。然后准备好JEB软件,启动JEB,将apk文件拖入窗口,JEB会自动开始反编译,整个过程可能会卡住一段时间,不用操作,等待反编译完成即可。在反编译之前可能会弹出一个设置弹窗,不需要修改设置,直接点完成即可。


等软件加载完,就可以看到反编译得到的汇编代码,以及软件包结构目录树,以下图为例:
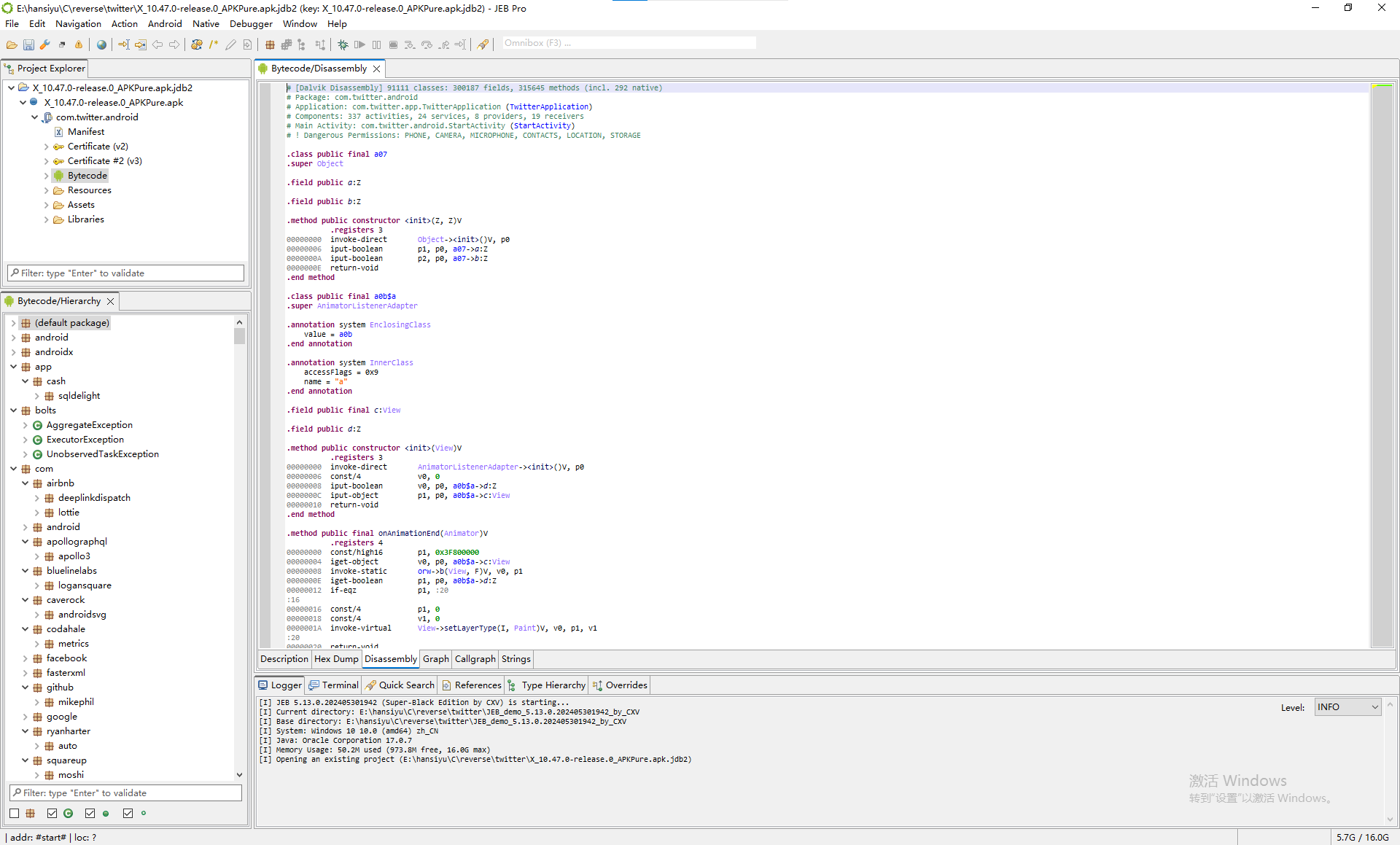
先来简单介绍一下这个界面。
首先是左上角,Project Explorer窗口是项目的,里面包含了项目的Manifest.xml、资源、动态库以及字节码等文件。
重点在于左下角的Bytecode/Hierarchy窗口,这个窗口显示软件(反编译得到的)源代码的目录树结构,这个窗口我们会经常用到。
右边最大的窗口就是资源浏览界面,Bytecode页的下面有几个标签页(Description、Hex Dump、String等),这几个标签页中,String会常用到,按照如图从左到右分别为项目描述、十六进制码、反编译汇编代码、代码结构图、调用结构图(这两个图在大型项目中一般会卡死,用来分析小项目还是挺好用的)、项目字符串。
大窗口的下面还有一个小窗口,包含日志、搜索等功能,默认窗口布局的标签从左到右分别是日志输出、调试终端、搜索、引用(References,不知道是不是这么翻译)、类型层级、函数重写。
模拟器侧的环境与上一篇文章保持相同即可。
寻找构造Authorization的代码
我们的目标是要找到请求中的authorization头,不过我们不知道这个头是从哪里生成的,但我们可以知道这个头会被哪里用到。我们可以按照上一篇文章的方法抓取一条请求,如下:
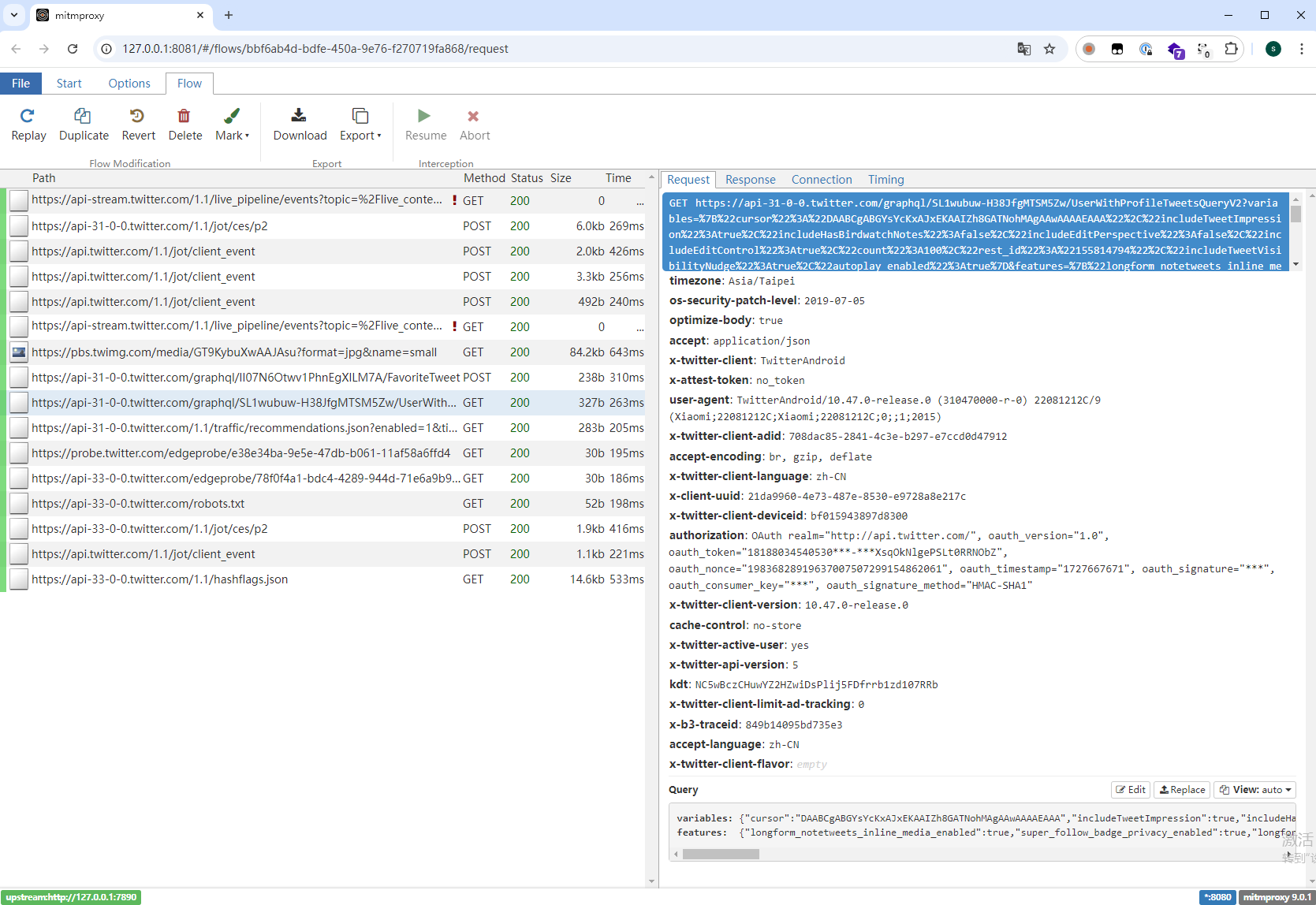
在对
1 | https://api-31-0-0.twitter.com/graphql/SL1wubuw-H38JfgMTSM5Zw/UserWithProfileTweetsQueryV2?...... |
接口进行请求时用到了这个头,我们可以顺藤摸瓜,直接在JEB中搜索auth头里面包含的字符串,比如OAuth,使用上文提到的String窗口即可:


找到了一堆结果,有请求url,也有一些参数,其中有一个结果比较可疑。我们双击进入,会跳转到汇编代码,按tab键可以转译成Java代码:
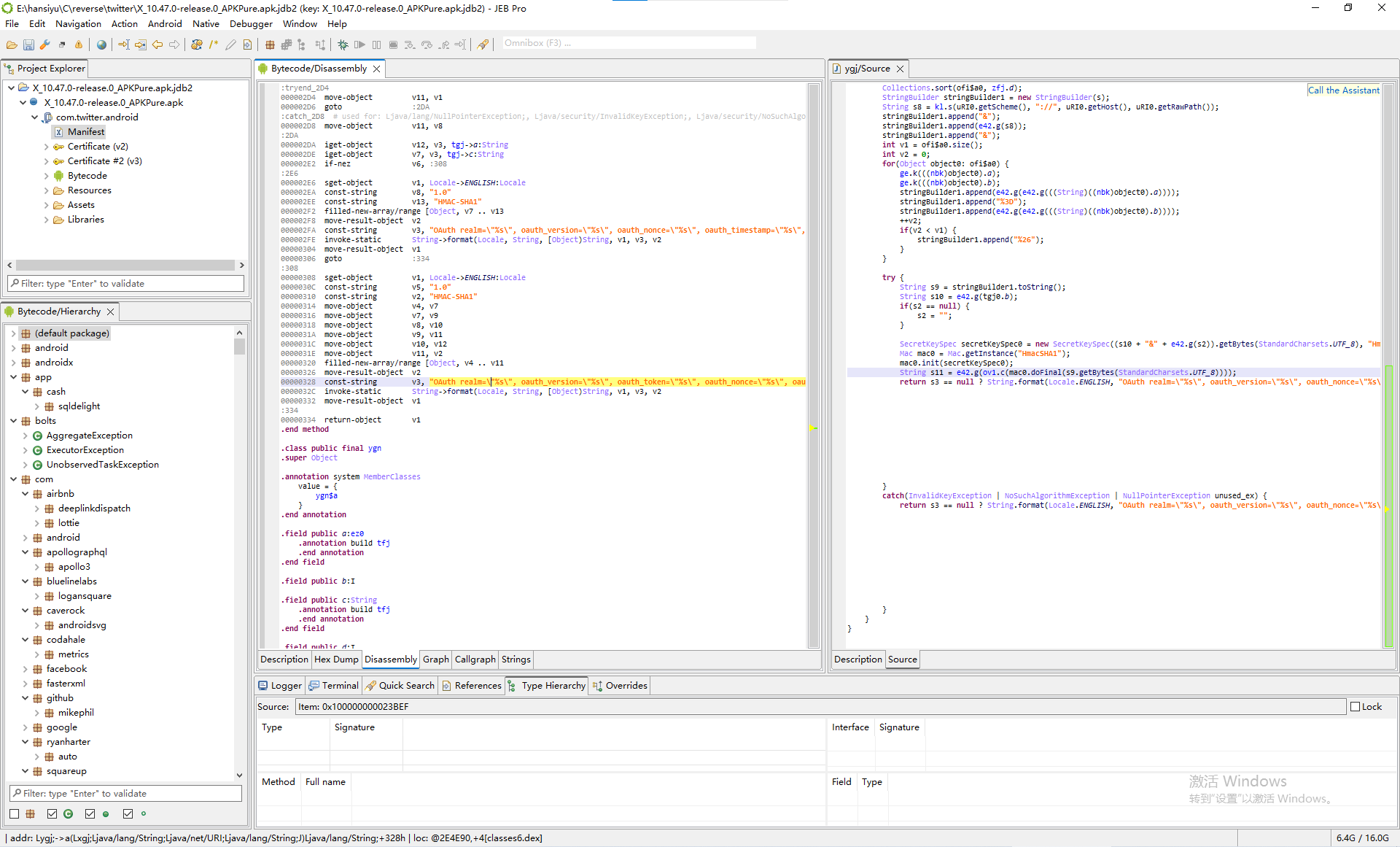

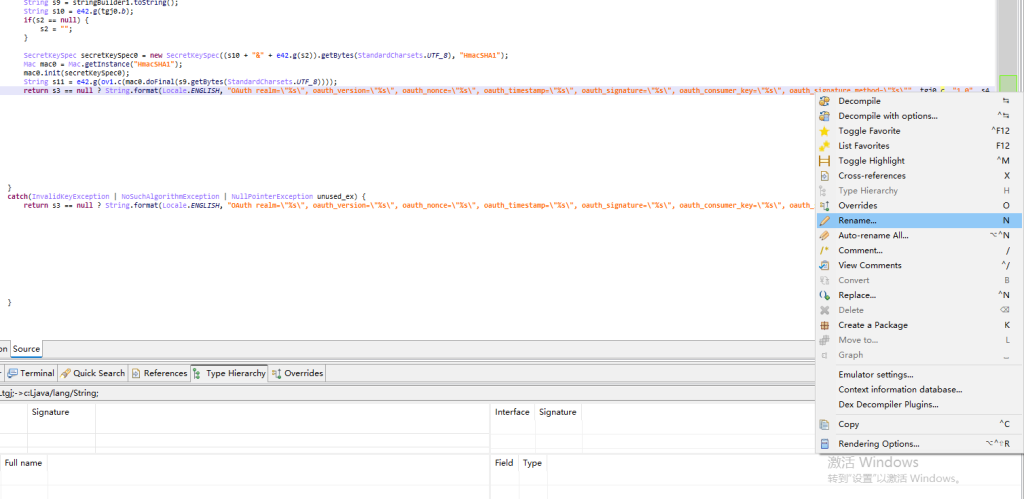
定位到这个字符串的代码是:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | try { String s9 = stringBuilder1.toString(); String s10 = e42.g(tgj0.b); if(s2 == null) { s2 = ""; } SecretKeySpec secretKeySpec0 = new SecretKeySpec((s10 + "&" + e42.g(s2)).getBytes(StandardCharsets.UTF_8), "HmacSHA1"); Mac mac0 = Mac.getInstance("HmacSHA1"); mac0.init(secretKeySpec0); String s11 = e42.g(ov1.c(mac0.doFinal(s9.getBytes(StandardCharsets.UTF_8)))); return s3 == null ? String.format(Locale.ENGLISH, "OAuth realm="%s", oauth_version="%s", oauth_nonce="%s", oauth_timestamp="%s", oauth_signature="%s", oauth_consumer_key="%s", oauth_signature_method="%s"", tgj0.c, "1.0", s4, s5, s11, tgj0.a, "HMAC-SHA1") : String.format(Locale.ENGLISH, // l:java.util.Locale "OAuth realm="%s", oauth_version="%s", oauth_token="%s", oauth_nonce="%s", oauth_timestamp="%s", oauth_signature="%s", oauth_consumer_key="%s", oauth_signature_method="%s"", // format:java.lang.String tgj0.c, // args:java.lang.Object[] "1.0", s3, s4, s5, s11, tgj0.a, "HMAC-SHA1" ); } catch(InvalidKeyException | NoSuchAlgorithmException | NullPointerException unused_ex) { return s3 == null ? String.format(Locale.ENGLISH, "OAuth realm="%s", oauth_version="%s", oauth_nonce="%s", oauth_timestamp="%s", oauth_signature="%s", oauth_consumer_key="%s", oauth_signature_method="%s"", tgj0.c, "1.0", s4, s5, "", tgj0.a, "HMAC-SHA1") : String.format(Locale.ENGLISH, // l:java.util.Locale "OAuth realm="%s", oauth_version="%s", oauth_token="%s", oauth_nonce="%s", oauth_timestamp="%s", oauth_signature="%s", oauth_consumer_key="%s", oauth_signature_method="%s"", // format:java.lang.String tgj0.c, // args:java.lang.Object[] "1.0", s3, s4, s5, "", tgj0.a, "HMAC-SHA1" ); } |
实际上这些反编译得到的代码是经过混淆的,比如tgj0.c或s4这种,这无疑会增加分析的难度,但是我们可以使用Rename或Auto-rename All来重命名成我们分析的结果。
接下来就是对Java代码的分析,实际上我个人认为,分析代码只能靠耐心和经验加上语言模型工具辅助(这个很有效果)。进行代码分析时,可以善用菜单栏的这几个按钮:

从左到右分别是跳转到指定地址、进一步跟踪代码(也就是跟直接双击代码一个效果)、后退到上一步、前进到下一步。
根据上面反编译得到的代码的特征来看,几乎可以确定这里就是构造Auth头的地方了,我们来分析一下这段代码。
首先最外层是try-catch,try和catch中都有构造auth的代码,对比这两个构造的区别,发现catch中的s11变量被替换成了空字符串,查找s11变量在构造的字符串中的位置,确定为oauth_signature,说明这里的try-catch是为了解决没有oauth_signature参数的情况,同时这个参数也是我们需要寻找算法的参数,所以catch这个分支对于我们分析来说没有帮助。根据观察catch的捕捉条件可以知道,走到该分支有可能是因为key错误、算法错误或空指针错误,说明该参数是在这个代码块中参与运算的,所以我们接下来重点关注try里面的代码。
从构造auth的代码向上往回找,是这一部分:
1 2 3 4 | SecretKeySpec secretKeySpec0 = new SecretKeySpec((s10 + "&" + e42.g(s2)).getBytes(StandardCharsets.UTF_8), "HmacSHA1"); Mac mac0 = Mac.getInstance("HmacSHA1"); mac0.init(secretKeySpec0); String s11 = e42.g(ov1.c(mac0.doFinal(s9.getBytes(StandardCharsets.UTF_8)))); |
这一段代码很明显是在进行一个HmacSHA1的运算,首先是
1 | SecretKeySpec secretKeySpec0 = new SecretKeySpec((s10 + "&" + e42.g(s2)).getBytes(StandardCharsets.UTF_8), "HmacSHA1"); |
这行代码构造了一个SecretKeySpec类,根据官方文档可知,这个类是一个用于加密密钥的类。密钥由 (s10 + "&" + e42.g(s2)) 生成,这一块我们后面再分析。最终密钥被编码为UTF-8字节码,然后被指定为使用HmacSHA1算法。
1 2 | Mac mac0 = Mac.getInstance("HmacSHA1"); mac0.init(secretKeySpec0); |
这一段代码是实例化了一个Mac运算,指定加密算法为HmacSHA1,并使用上面创建的密钥类进行初始化。至于HMAC算法的具体细节,可以在上一篇文章中找到。
最后是调用doFinal对s9进行加密运算,将值然后调用ov1.c和e42.g得到最后的签名s11。
在这一段代码的分析中,有部分方法的作用尚不明确,我们将逐个分析其功能。
首先是s10字符串,其来自于
1 |
查看e42类的g方法,代码比较多我就不贴出来了,经过分析得知这个方法的作用是进行url编码的,这里传入的参数是tgj0.b,查找这个字符串的来源为:
1 2 |
右键this.a的a部分,选择Cross-References,可以看到该参数的getter、setter、设置、调用、获取等操作。

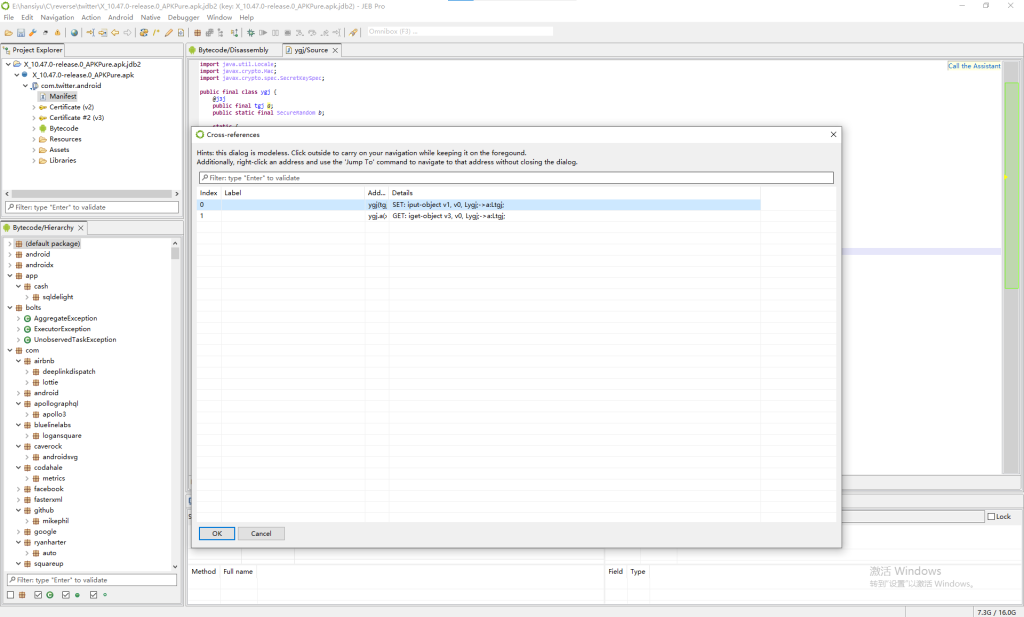
双击SET方法,找到该参数的setter如下:
1 2 3 | public ygj(@j3j tgj tgj0) { this.a = tgj0; } |
在实际的逆向分析操作中,可以尝试使用frida来hook这个参数的setter方法,来查看this.a的值到底是什么,有关操作在上一篇文章中已经介绍过了。在本文中,因为篇幅问题,就不再重复这个操作了,因为通过上一篇文章的结论我们已经可以知道s10是Consumer secret常量,安卓端固定为Bcs59EFbbsdF6Sl9Ng71smgStWEGwXXKSjYvPVt7qys。
然后是s2参数,该参数是 public final String a(@tfj xgj xgj0, @j3j String s, @j3j URI uRI0, @tfj String s1, long v) 方法被调用时通过xgj0传入的,s2就是该对象的b属性,该参数为null时s2为空字符串,猜测是未登录或登录失效的情况。右键a选择Cross-References,找到调用a方法的地方,找到invoke的结果,一共有两个,随便选择一个(因为我也不知道具体是哪个)双击进入,定位到ahj.A2(),调用处代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | @j3j public final String A2(@tfj isu isu0, @j3j b h8d$b0, @j3j URI uRI0, @tfj t7d t7d0, long v) { String s = null; xgj xgj0 = isu0 == null ? null : isu0.a; ygj ygj0 = this.d; String s1 = h8d$b0.name(); if(t7d0 != null) { twc twc0 = t7d0.a(); if(twc0 != null && "application/x-www-form-urlencoded".equals(twc0.getValue())) { try { s = qpy.I(t7d0); } catch(IOException unused_ex) { } } } return ygj0.a(xgj0, s1, uRI0, s, v); } |
根据代码可知来自于isu0.a,继续向上查找,重复上述步骤(总之就是一直用Cross-References一直向前查找,因为调用比较多,因为篇幅问题就不全部写出来了)...定位到这个值来自于UserIdentifier类(具体来自于 cvu.L4 的 isu isu0 = TwitterNetworkOAuthObjectSubgraph.get().q3().a(this.Z); 其中TwitterNetworkOAuthObjectSubgraph.get().q3().a是用来处理与UserIdentifier对象相关的业务逻辑,而this.Z是UserIdentifier类),最终跟踪到该值来自于isu.a.b,同样的方式使用frida对该值进行监听,可以得知该值来自于登录请求的OAuth token secret。
接下来是s9,该值来自于stringBuilder1,stringBuilder1的最初赋值的代码如下:
1 | StringBuilder stringBuilder1 = new StringBuilder(s); |
其中的s使用同样的方法,跟踪到h8d的b方法,这个值是一个枚举,值为GET/POST/PUT/DELETE/HEAD。然后拼接了一个&符号,随后是s8字符串,其如下代码:
1 |
从特征上来看,是一个完整的url,实际也可以进行验证。s8后又使用一个&符号,随后是拼接请求参数,具体的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 | int v1 = ofi$a0.size(); int v2 = 0; for(Object object0: ofi$a0) { ge.k(((nbk)object0).a); ge.k(((nbk)object0).b); stringBuilder1.append(e42.g(e42.g(((String)((nbk)object0).a)))); stringBuilder1.append("%3D"); stringBuilder1.append(e42.g(e42.g(((String)((nbk)object0).b)))); ++v2; if(v2 < v1) { stringBuilder1.append("%26"); } } |
完成上述所有步骤后,构成字符串s9,并进行HMACSHA1加密,最后得到我们需要的oauth_signature。当然,其他参数也可以按照这个流程分析得到。
更偏门的方法
有些时候,因为算法过于复杂,或者APP数据处理逻辑混乱,我们可能很难分析出其算法,这个时候我们就需要使用一些较为偏门的方式来进行数据采集了。有关这一部分,等后面有空再写一篇文章详细说明了,毕竟“需要提前了解的信息”这一节可不是白写的,里面的知识后面用得上的。
- 这部分内容在“请求流量分析”一节 ↩︎
- 不同于预处理和编译这两个步骤,这一步会生成一个实际的文件,后缀名通常是.o(linux
)或.obj(windows) ↩︎ - Windows平台的动态库后缀一般是.dll(Dynamic-link library的缩写),Linux平台一般是.so(Shared Object的缩写) ↩︎
- Windows平台的可执行文件是PE格式,后缀一般是exe;Linux平台的是ELF格式,没有固定后缀;我自己开发的操作系统KNOS的可执行文件是我自己定义的KAL格式,后缀名为.kal,文章还没有写到这里来,但是代码可以参考我的GitHub项目(很久以前写的东西,很乱了,后来重构了一下,但是烂尾了)。 ↩︎