




以前在学校就有接触到爬虫相关的工作,直到现在还在写爬虫(呃...),最近发现光靠网页爬虫数据,不管是从频率还是数据都有一定的限制。为了绕过这些限制,最近我开始尝试通过APP来进行数据采集,不过有些APP对数据采集不太友好,比如请求需要签名、SSL/TLS加密等等,今天就以X平台为例来解决这个问题。
注意:
本文有小部分内容由AI辅助创作,部分内容的真实性存疑,请自行判断。
本文会使用到一些方法绕过GFW,请在使用互联网时遵守当地的相关法律法规。
本文涉及到软件逆向分析,请注意在实践过程中的法律问题。
根据《中华人民共和国刑法》第286条:
违反国家规定,对计算机信息系统功能进行删除、修改、增加、干扰,造成计算机信息系统不能正常运行,后果严重的,处5年以下有期徒刑或者拘役;后果特别严重的,处5年以上有期徒刑。
违反国家规定,对计算机信息系统中存储、处理或者传输的数据和应用程序进行删除、修改、增加的操作,后果严重的,依照前款的规定处罚。
故意制作、传播计算机病毒等破坏性程序,影响计算机系统正常运行,后果严重的,依照第1款的规定处罚。
常规的数据采集
学习或开发过爬虫的同学都知道,常用的数据采集方式有几种:
一是网页抓取,即通过requests或其他类似的网络工具直接对页面进行请求,并通过xpath等工具处理返回的页面文件,多见于内容不经常变化的网页或纯静态页面数据采集。这种方法的优点是简单易用,缺点是当网页结构发生变化时,需要调整解析规则。
二是API接口请求,即通过浏览器开发者工具,抓取到数据的请求接口;或者使用官方公布的API接口。一般来说,前后端分离的系统都会有单独的数据请求接口,返回格式多为json。该方法处理简单,速度快,但有可能会被服务器限制请求速率。且如果没有官方的接口文档,有些时候返回的数据比较难以分析。部分官方开放接口可能限制较多,甚至需要收费使用。
三是使用selenium模拟浏览器行为进行动态网页采集,该方法适用于网页通过js动态加载数据的情况。但通过模拟用户操作的方法,可以尽可能减少采集行为被发现、账号被风控的情况发生。同时该方法缺点也很明显,即速度较慢,占用系统资源较多,尤其是进行多线程采集的情况,每个线程需要单独启动一个浏览器内核,对资源需求极高。
除此之外,还有一些较为特殊的数据采集方式,比如某弹幕网站的APP平台就使用到了gRPC接口用于获取视频弹幕信息,以及socket套接字用于获取直播弹幕和礼物数据流1。还有使用RSS订阅源进行数据采集2的方法,该方法优点是通用、开发简单,有很多线程的库可以直接使用,并且开发一套RSS采集爬虫基本上就可以在所有RSS订阅源通用;缺点是RSS数据量一般来说比较少,很多网站甚至没有官方的RSS订阅连接,还有类似某乎这样的网站,需要登陆才能获取RSS订阅3。
基于APP接口的数据采集
由于X平台的网页端限制较大,本文尝试使用APP的接口来进行数据采集,不知道能否比网页端情况好一些。
APP接口请求数据的方式与网页类似,除了上面一节提到的弹幕采集这种特殊情况以外,基本上也是以HTTP请求为主,所以实际上我们只需要构造好请求数据,然后请求对应的HTTP接口即可。不过实际上,整个开发过程中,最难的一步就是寻找需要的HTTP接口,以及解析需要发送的请求数据。
下面,我们先了解一下需要用到的基本原理和理论知识,然后尝试以X平台为例,进行逆向分析和数据采集。
需要提前了解的信息
超文本传输协议(http)
超文本传输协议,全称为HyperText Transfer Protocol,更常用的说法是http协议。HTTP协议七层OSI模型的应用层,关于七层OSI模型的相关内容,可以在这里了解到。HTTP最开始的设计目的是为了传输HTML(HyperText Markup Language,超文本标记语言)页面。其请求的资源通过URI(Uniform Resource Identifiers,统一资源标识符,与URL不同)来进行标记。
关于HTTP的发展和历史故事,这里就不详细描述了,感兴趣的同学可以到Wikipedia上面了解一下。这里主要讨论一下HTTP的技术相关问题。
在很久很久以前......well,我并不是要讲什么故事,我想说的是在很久以前我已经写过一篇文章,来简单介绍HTTP协议请求方法了,这篇文章可以在这里看到。关于这篇文章当中已经写过的内容,就不再重复了。这里主要对请求和响应结构进行一下补充。
在之前那篇文章中提到了,报文是有三部分组成,分别为报头、空行和报体,实际上在报头之前还有请求行,以本站主页(https://kalinote.top/)为例,请求的完整报文如下:
1 2 3 4 5 6 7 8 9 10 11 12 | GET https://kalinote.top/ HTTP/2.0 upgrade-insecure-requests: 1 user-agent: Mozilla/5.0 (Linux; Android 9; SM-S906N Build/PQ3B.190801.06281541; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/91.0.4472.114 Mobile Safari/537.36 accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9 x-requested-with: com.android.browser sec-fetch-site: none sec-fetch-mode: navigate sec-fetch-user: ?1 sec-fetch-dest: document accept-encoding: gzip, deflate accept-language: en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7 content-length: 0 |
实际上这是一个HTTPS的GET请求,其版本为2.04,在该请求中,第一行为请求行,其格式为:
1 | 请求方法|空格|URL|空格|协议版本|回车符|换行符 |
后面的内容,每一行为一个请求头(Header),每个请求头一般都有自己的意义,比如user-agent(UA,用户标识或用户代理)一般用于服务器识别请求发出的客户端,在上述例子中的请求头的UA为安卓9系统默认浏览器的UA,这一点在x-requested-with中也体现到了(其值为浏览器包名)。
实际上,各网站一般会有自己的请求头参数需求,缺少某些参数可能会导致权限错误(401)或Bad Request(400)等其他请求失败的情况发生。
使用上述请求后,服务器返回了如下数据:
1 2 3 4 5 6 7 8 | HTTP/2.0 200 server: nginx date: Tue, 09 Jul 2024 08:58:05 GMT content-type: text/html; charset=UTF-8 vary: Accept-Encoding x-frame-options: SAMEORIGIN strict-transport-security: max-age=31536000 content-length: 60097 |
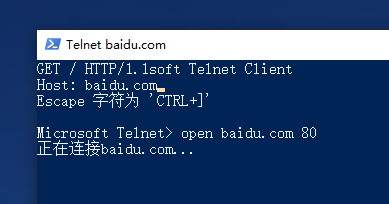
当然,这些操作都是我们在浏览器中输入了网址后,浏览器自动帮我们完成的,我们也可以使用类似telnet的工具手动来完成这个过程,比如向baidu.com发送一个http/1.1请求:
在Powershell中执行命令:
1 2 | PS C:\Users\Administrator>telnet Microsoft Telnet>open baidu.com 80 |
然后输入如下请求数据(1.1的格式与2.0有一些不同,比如在HTTP/1.1中Host是必须的,URL的位置为URI):
1 2 | GET / HTTP/1.1 Host: baidu.com |
因为telnet软件在输入时不会清屏,所以输入的字符会和原来的字符重叠,这是正常的情况。
服务器返回结果如下:
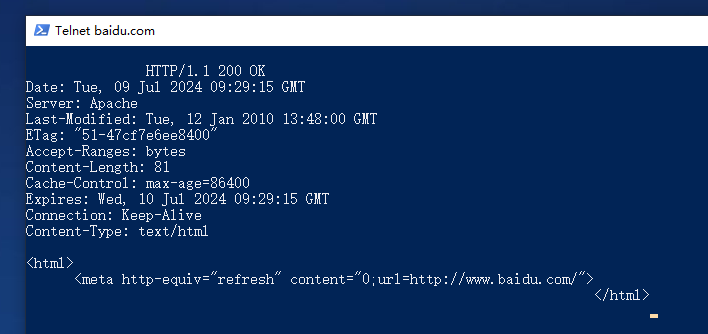
其内容只有一句立即重定向到https://www.baidu.com/的代码,显然,百度已经不支持http请求了5(?)。
实际上,HTTP运行在TCP协议之上(当然,是在HTTP3.0之前的版本,HTTP3.0改成了UDP传输,这个后面有机会再细说),所有数据都是明文传输,所以基本没有什么安全性。如下图,尝试使用http访问baidu.com,所有数据都直接被抓取到了。
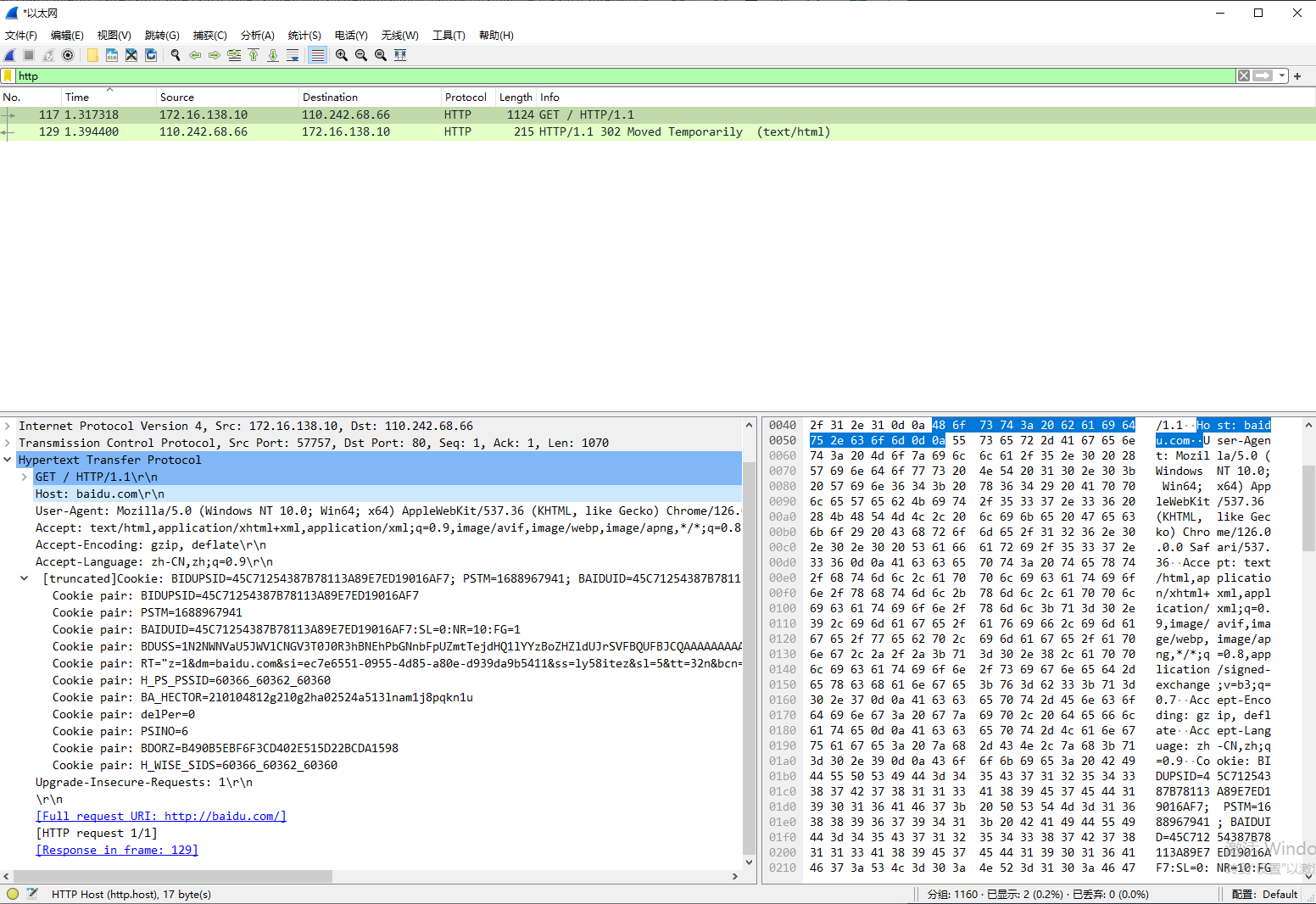
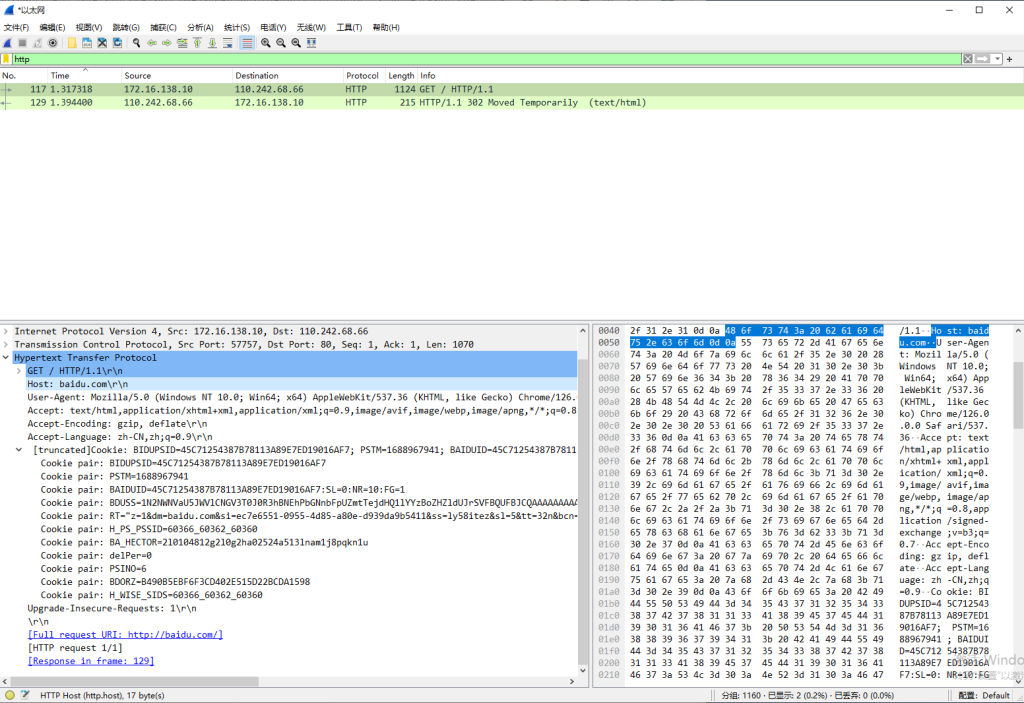
这个问题还会导致如果用户被中间人攻击,所有的账号密码、cookies都有泄露的风险,并且也存在传输的数据、甚至是下载的文件被替换的风险。很久以前大多数网站和服务都是使用http协议传输数据,所有数据都在网络上裸奔,当时连接公共网络极其危险6,如果局域网内缺乏ARP攻击的防御,一旦被攻击者利用,用户的信息安全就会受到极大的威胁。
SSL/TLS以及超文本传输安全协议(https)
为了解决上述问题,超文本传输安全协议出现了。超文本传输安全协议,也就是现在最为常用的https,该协议还是利用HTTP进行通信,但使用了SSL/TLS进行传输数据的加密。实际上,从数据上来说http和https没有什么区别,只是https工作在安全协议之上,所有的数据通过加密传输,安全协议向http进程提供一个用于传输的TCP套接字,https进程向该套接字发送和接受数据。所以从本质上来说,https并不是一个单独的协议,而是指的通过安全协议进行数据传输的http。
https中的所有报文都是被加密的,攻击者只能监控到有流量传输,但是没办法获取到流量内容,比如使用wireshark对本站请求进行抓包,结果如下:
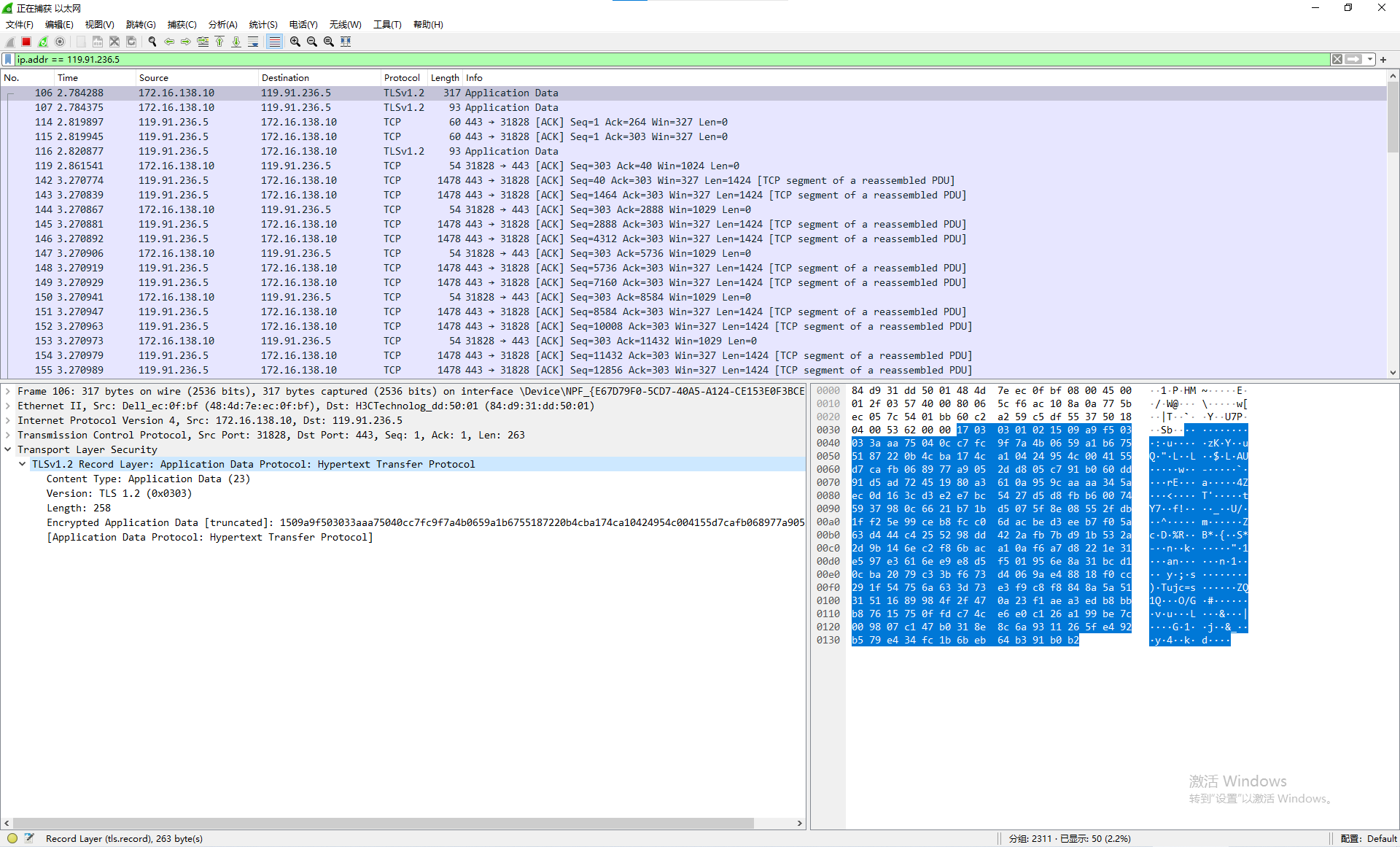
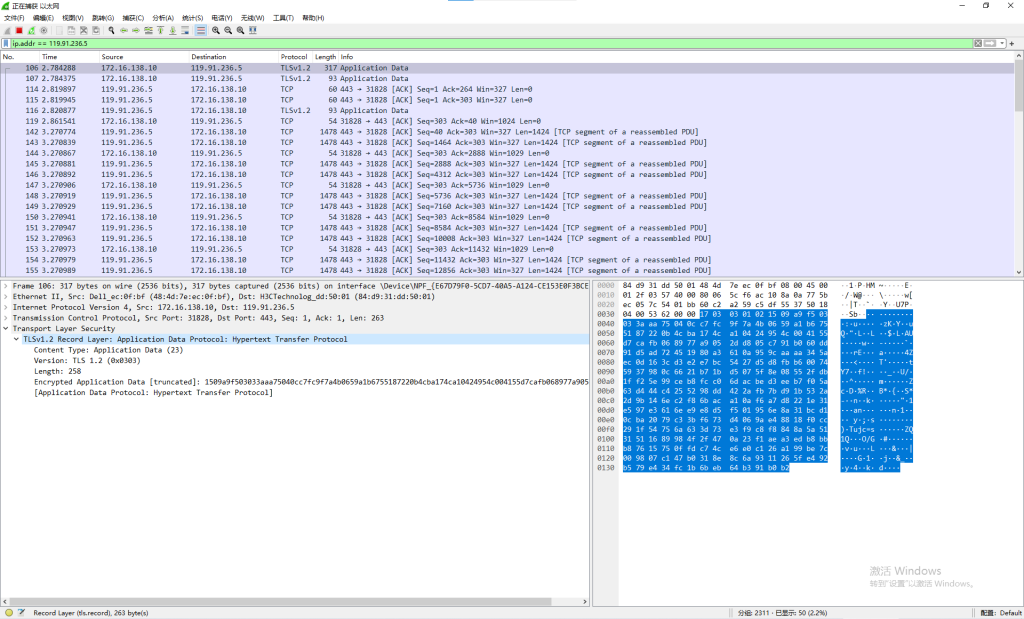
那么SSL/TLS是如何对数据进行加密的呢?
首先要明确的是,虽然SSL和TLS经常同时出现,但实际上它们是两个不同的协议,其全称分别为Secure Sockets Layer(SSL)和Transport Layer Security(TLS),TLS是基于SSL3.0的改进和标准化版本。由于SSL存在大量安全漏洞,所以已经几乎被所有浏览器弃用,目前使用最多的为TLS1.2和TLS1.3。
下面是TLS对数据进行加密传输的过程:
首先是握手(Handshake)阶段,在这个阶段,客户端和服务器协商加密算法,验证身份,并生成会话密钥。客户端会首先发送支持的TLS版本、加密算法套件列表和一个随机数7。服务器接收到相关数据后会从客户端提供的选项中选择一个TLS版本和加密算法套件8,并生成一个随机数。然后将这些信息连同证书(后面会提到)一并发送给客户端,客户端会验证证书的有效性和真实性。确认证书可信后,客户端会生成一个新的随机数并使用服务器的公钥加密这个随机数,然后发送给服务器。服务器使用其私钥解密,得到客户端的随机数。最后客户端和服务器使用各自的随机数和协商的算法生成共享的会话密钥,这个密钥将用于对实际传输的数据进行加密。
完成上述步骤后,握手阶段完成,服务器和客户端之间就可以进行实际的数据传输工作了。
在数据传输过程中,数据发送方会先使用会话密钥和握手阶段协商的对称加密算法进行数据加密,为了确保数据的完整性,发送方还会计算数据的消息认证码或哈希值,并将其和数据一起发送到服务端,确保数据在传输中没有缺失或被篡改。接收方收到加密数据后,会使用相同的会话密钥对数据进行解密,最后通过认证码或哈希值对数据进行完整性验证。
服务器和客户端对话完成后,通过发送关闭通知9来终止TLS连接,确保连接安全关闭。
中间人(Man-in-the-Middle, MITM)攻击
在前面提到,http协议的所有数据都是明文传输,所以容易遭受到攻击,其中最常见的就是中间人攻击。
中间人攻击指的是指攻击者在两方通信之间插入自己,窃听、篡改或伪造双方之间传输的数据。很多年前,我还在读初中的时候,当时在互联网上接触到了这个概念,瞬间就来了兴趣。当年还有大量的网站和软件(比如旧版百度贴吧和QQ的部分服务)使用的是http协议。当时我给我的手机root后刷了个bt5系统10,然后在学校门口的快餐店玩渗透,跑漏洞利用把人家路由器的后台密码给改了?然后还通过ARP欺骗攻击11到处抓别人的数据,替换文本和图片,替换别人下载的文件成木马(有一种艾登·皮尔斯的感觉)。不过好在当时跟店主关系不错,也没酿成什么严重后果,所以没出啥事,现在想想还真够悬的。(所以当年的公共网络是真挺危险的)
呃,扯远了,说回中间人攻击。
中间人攻击的基本原理就是攻击者拦截客户端和服务器之间的通信,并捕获和修改网络上的数据包。攻击者对于客户端,会伪装成服务器;而对于服务器则伪装成客户端,所有服务器和客户端的数据都会从攻击者主机上经过。一旦成功拦截和冒充身份,攻击者可以窃听双方传输的敏感数据(如cookies、个人信息等),或者篡改传输的数据内容。
TLS加密可以有效防御MITM攻击,TLS握手过程中使用公钥加密算法来安全地交换会话密钥,然后使用对称加密算法保护数据传输。攻击者即使拦截了加密数据,因为没有会话密钥,所以也无法解密内容。同时,因为有Diffie-Hellman(DH)和椭圆曲线Diffie-Hellman(ECDH)12这样的密钥交换协议,所以即使攻击者能够截获交换信息,也无法计算出会话密钥。
因为TLS握手的过程中,客户端和服务器会使用一个生成的随机数,并通过这些随机数生成密钥,所以攻击者也无法通过规律来预测密钥。
因为如上原因,TLS可以有效防范MITM攻击,但同时也给我们后续的工作带来了一些阻碍。
数字证书
在上面提到过,客户端和服务器建立连接时,服务器会向客户端发送数字证书,客户端会确认该证书来自可信服务器,而非第三方攻击者。数字证书的作用就是用于让客户端确认正在通信的服务器是可信服务器,而不是攻击者伪造的服务器,以此保证安全通信。
数字证书由一个广泛信任的第三方机构签发(证书签发机构,CA),签发的证书里面包含了一些信息,比如:网站或组织名,用于加解密数据的公钥,证书的有效期以及CA机构的数字签名。上面提到的会话密钥,就是通过证书中的公钥来生成的。
测试环境准备
了解了以上基础知识以后,我们就可以实际动手操作了。
手机/模拟器
首先我们需要先准备好测试环境,最基础的就是需要准备一台拥有root权限的手机,或是使用模拟器。但是在选择模拟器时需要注意,如果计算机开启了Hyper-V,Windows系统会运行在Hypervisor之上,但多数模拟器都无法在此状态下启动。所以在安装模拟器之前,建议先在程序与功能中关闭Hyper-V和虚拟化平台功能,如果一定要保留该功能,可以选择Hyper-V版的BlueStacks13。本文使用雷电模拟器。
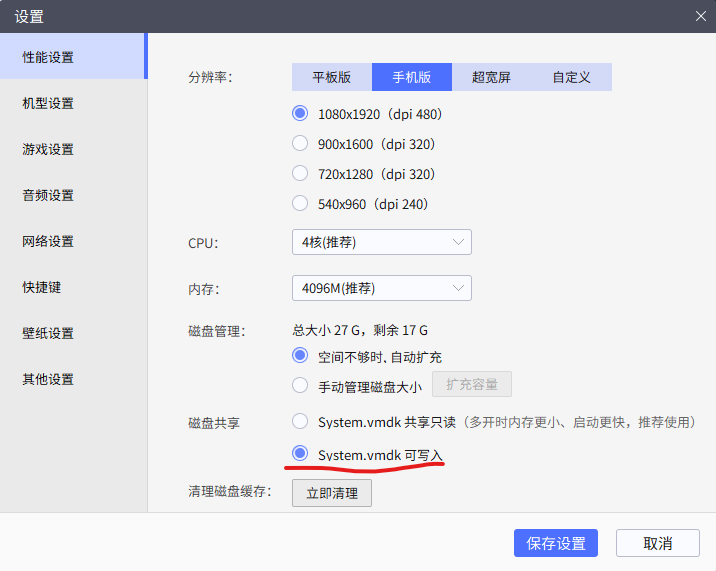
完成模拟器安装和启动后,首先进入设置,在性能设置页面将磁盘共享设置为System.vmdk可写入状态,否则系统分区为只读。
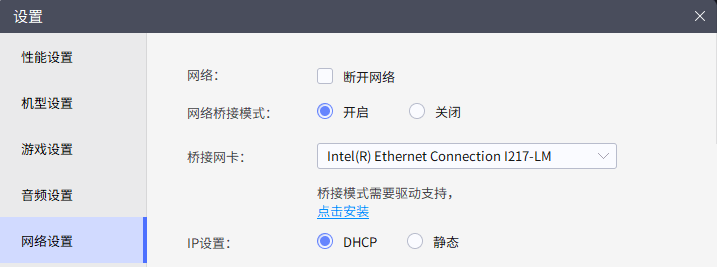
在网络设置中,将网络桥接模式打开,网卡选择到互联网网卡(不知道的可以在 控制面板\网络和 Internet\网络连接 中确认),然后按照提示点击安装驱动。
然后在其他设置中开启root权限。
如果有些模拟器默认没有开启ADB连接,或不支持远程ADB连接的,可能需要手动进入模拟器或安卓设置中开启。
最后在模拟器中下载和安装X客户端。
抓包工具
我们需要通过APP的接口来采集,最基本的前提条件就是需要知道APP的接口到底是什么,我们有两种方法来确定接口,一是对软件进行逆向,从代码中分析接口,这种方法工程量巨大,显然不可行;但幸运的是,我们可以使用另一种较为简单的方法来寻找接口,即通过抓包工具获取数据接口。
本文使用mitmproxy工具进行抓包,该工具虽然功能不太多,但是足够我们使用了。不过如果你有其他熟练使用的抓包工具(比如常用于流量分析的wireshark或fiddler等,都可以使用)。
mitmproxy包含3个工具,其中我们需要使用到的是mitmweb。

打开powershell,输入如下命令即可启动mitmweb:
1 | PS C:\Users\Administrator>mitmweb |
启动后会自动打开一个网页:
启动mitmweb后,会启动8080端口,用于数据捕获。此时将需要抓包的软件的代理地址设置为8080即可抓取到流量。不过因为上面提到过的原因,抓包软件实际上是无法解析https数据的,只能抓取到未加密的http数据,因为抓包软件不知道请求的会话密钥,无法解密数据。
不过好在我们可以通过安装抓包软件自签的证书来解决这个问题,安装了抓包软件的证书后,抓包软件可以单独向服务器发送请求,接收到服务器请求并解密后,再加密并继续向客户端发送请求,此时客户端收到的请求是由抓包软件的证书进行加密的。

接下来我们安装抓包工具的证书。首先进入模拟器,打开设置页面,将网络代理地址设置到主机的8080端口:
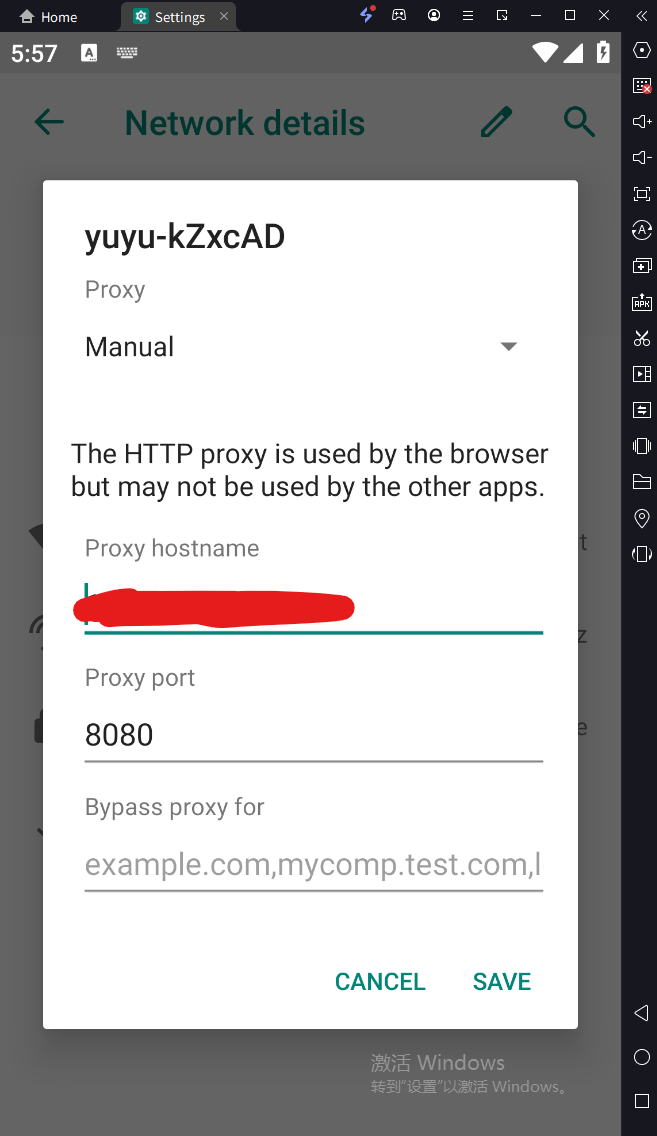
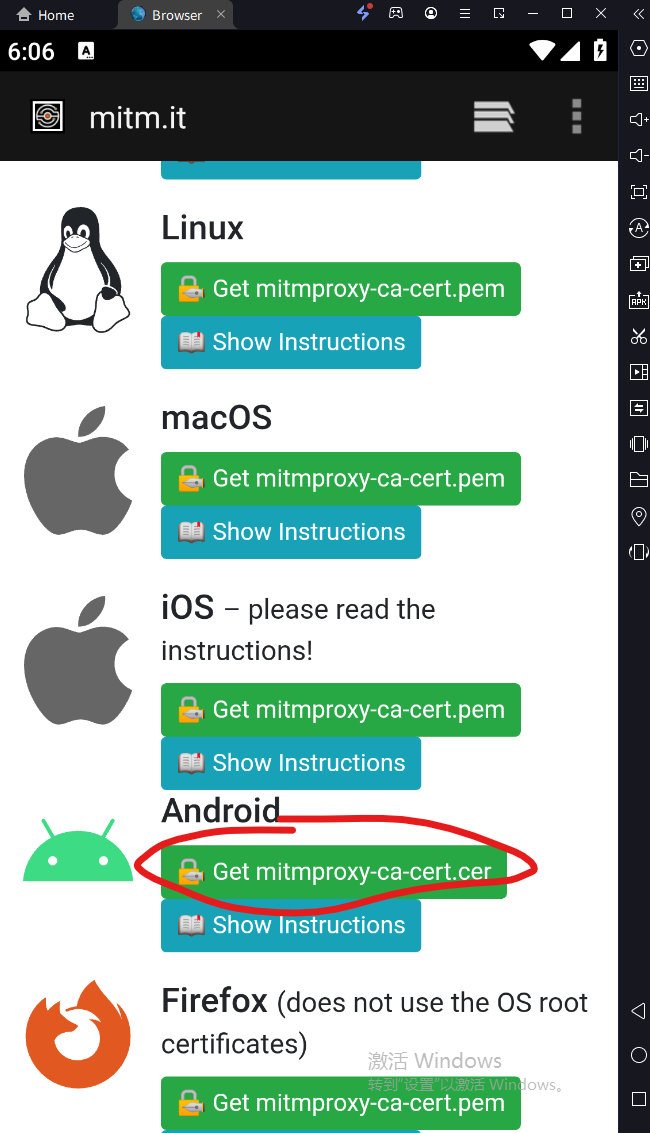
然后打开模拟器浏览器,网址输入mitm.it,看到如下页面说明代理设置成功。下拉页面,找到Android,点击Get mitmproxy-ca-cert.cer下载和安装证书,具体的安装步骤可以参考这个(这个步骤很简单,根据提示操作即可14)。
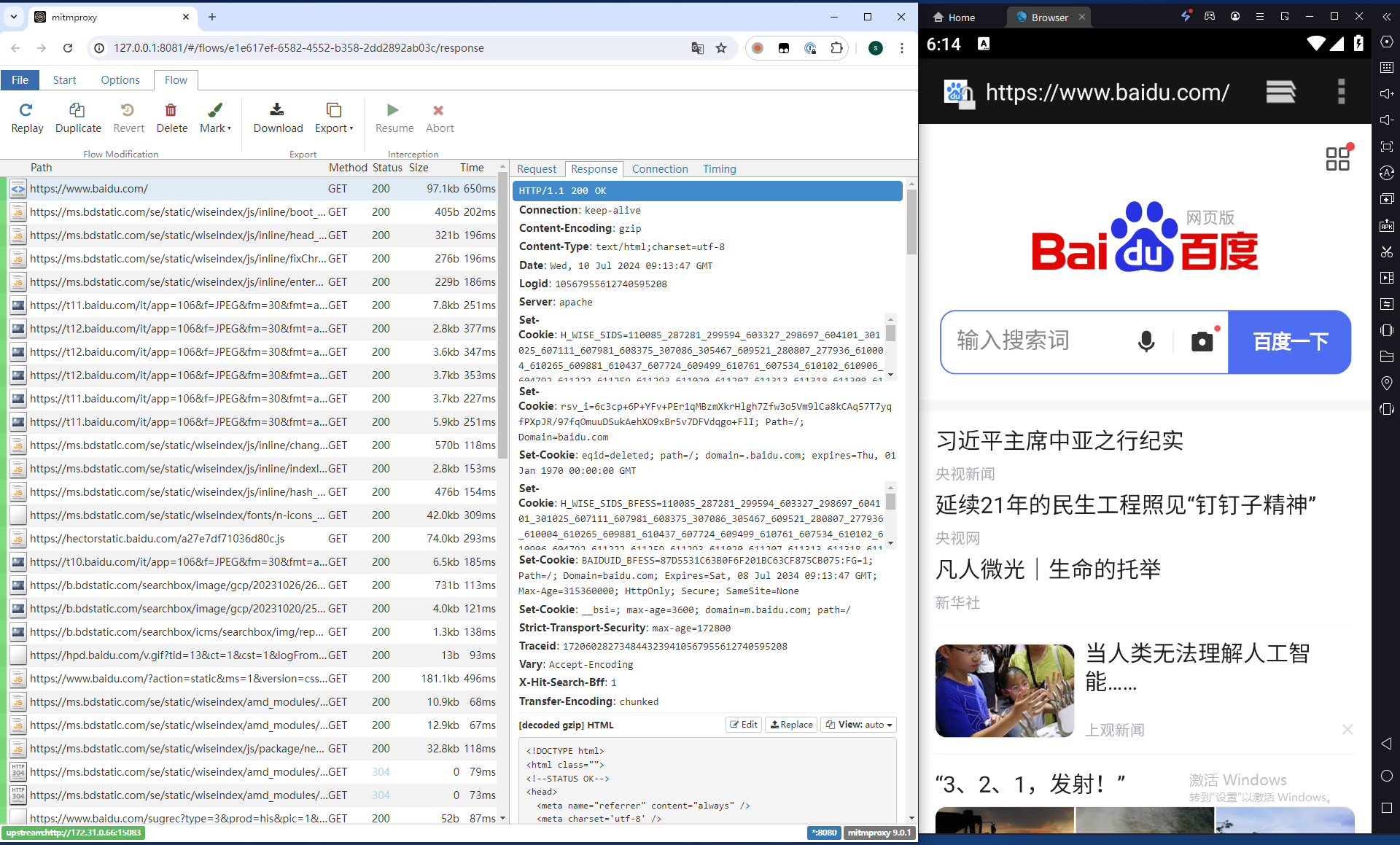
完成证书安装后,即可抓取到https流量:
最后,因为有GFW的存在,我们没办法直接通过中国大陆的互联网访问X平台的服务器,所以我们需要设置前置代理,使用如下命令重新启动mitmweb以设置前置代理(假设代理地址为http://ipaddr:port):
1 | PS C:\Users\Administrator> mitmweb --mode upstream:http://ipaddr:port |
完成上述这些步骤后,我们可以尝试打开X,从理论上来说我们已经可以正常抓取到X的流量数据了,但是实际上APP仍然无法联网,查看mitmweb输出,有以下报错内容:
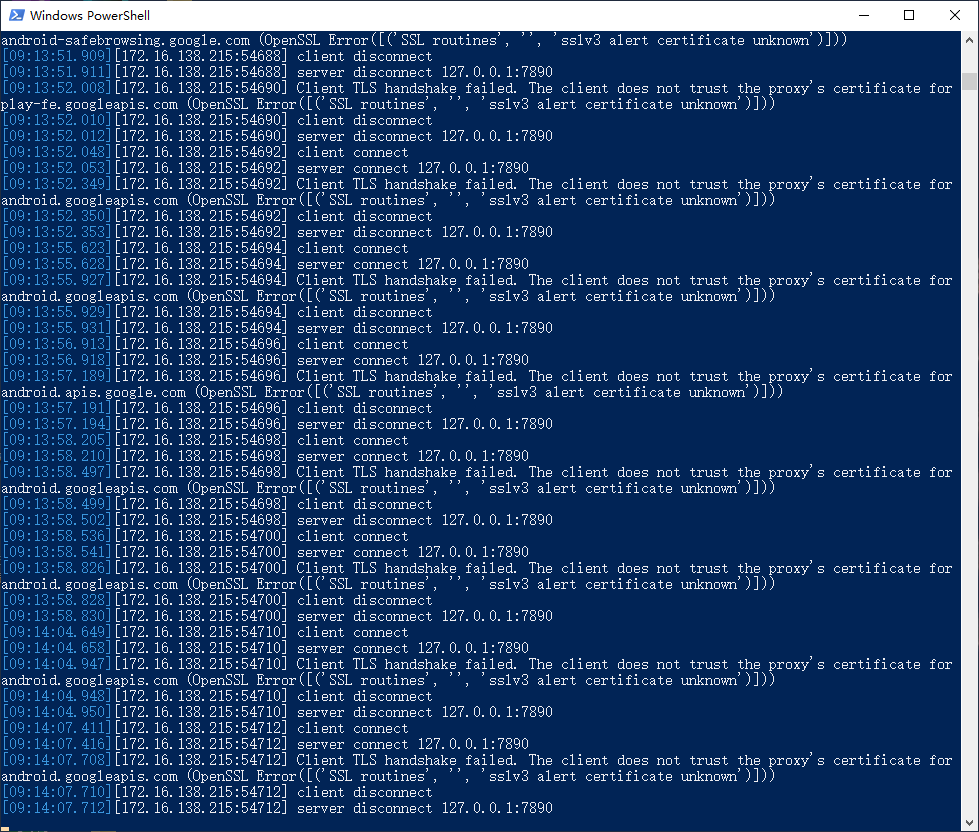
出现这种情况,是因为X采用了SSL固定(SSL Pinning)技术。SSL绑定是一种安全技术,用于防止中间人攻击。简单来说,就是X平台在软件开发时就将服务器证书预先保存到了APK安装包中,在与服务器建立SSL/TLS连接时,会验证服务器传回的证书与预先保存的证书是否一致,如果证书匹配,则会继续连接,否则连接将被拒绝(not trust)。
为了解决这个问题,我们有两个办法,第一是反编译APK,去掉证书固定验证相关的内容,然后重新编译APK并安装。这种方法的优点是只需要一次操作就可以在各平台安装修改过的APK,缺点是操作难度比较高。第二是通过注入代码的方式动态绕过SSL Pinning,本文将主要采取这种方法。
安卓调试桥(ADB)
在安装注入代码的工具之前,还需要先了解一个用于安卓调试的工具,即安卓调试桥(ADB, Android Debug Bridge),顾名思义,该工具用于对安卓系统进行调试。该工具有许多功能,例如安装和调试应用,传输文件,操作安卓底层linux等。
安装ADB工具,可以直接去官网下载,不过因为GFW的问题,这一步可能需要使用代理。当然,如果你已经安装过Android Studio,那么AS应该已经自动安装过ADB工具了。还有,部分模拟器自带ADB工具,你可以将下一步的环境变量设置到对应位置。
完成下载后,将文件解压到某个位置,然后复制该位置的路径,打开Windows环境变量,在path中加入该路径(直到adb.exe同目录,也就是*\platform-tools 这一级),如下图:
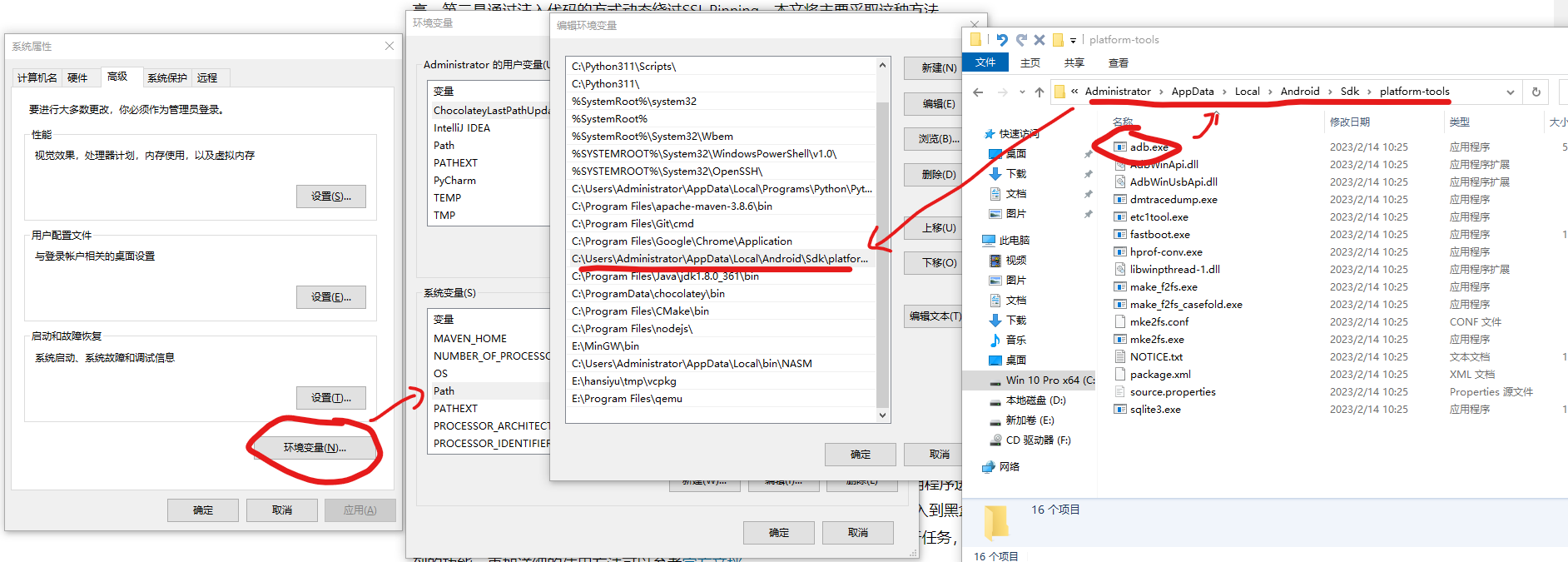
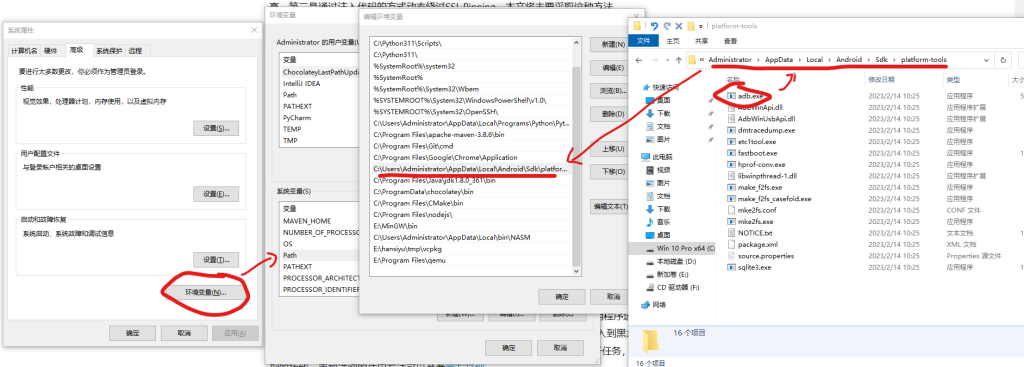
完成上述步骤后,打开命令行输入adb --version应该可以得到如下结果:
1 2 3 4 | PS C:\Users\Administrator> adb --version Android Debug Bridge version 1.0.41 Version 34.0.0-9570255 Installed as C:\Users\Administrator\AppData\Local\Android\Sdk\platform-tools\adb.exe |
从理论上来说,如果你在安装模拟器这一步操作正确,ADB会自动连接到模拟器,此时输入adb devices结果如下:

如果输入该命令后结果为空,也可以输入 adb connect 模拟器IP:PORT 来手动连接。一般来说,除非模拟器特别修改过(比如Bluestack会随机指定端口)外,ADB默认段口为5555。
如果是手机,远程连接方法和模拟器类似,USB连接在安装好驱动后,ADB会自动进行连接。
动态分析调试工具
不通过反编译+回编修改代码的方式,要绕过SSL固定,我们就要想办法在代码执行过程中,修改已经写好的对证书验证的代码逻辑。frida工具可以帮我们实现这一目标。
Frida是一个专门用于逆向和分析的动态分析和调试工具,用于在运行时对应用程序进行内存中的修改,该软件本身在Github开源。frida可以通过API接口,让我们将自己编写的脚本注入到黑盒进程的内存中,并且是动态注入,无需对代码反编译。frida工具非常强大,可以完成很多逆向分析任务,本文只会介绍需要用到的功能,更加详细的使用方法可以参考官方文档。
frida分为客户端和服务端,其中客户端部署在主机上,服务端部署于模拟器或手机内。客户端依赖于Python环境,所以需要先安装Python,然后创建一个工作项目文件夹,用于存放相关文件,进入该文件夹,使用venv创建一个虚拟环境:
1 2 | PS C:\Users\Administrator> cd E:\reverse\twitter PS E:\reverse\twitter> python -m venv .venv |
激活虚拟环境,并在该虚拟环境中安装frida:
1 2 3 | PS E:\reverse\twitter> .\.venv\Scripts\Activate.ps1 (.venv) PS E:\reverse\twitter> pip3 install frida # 当然,有能力的也可以自己下载源代码编译安装 |
完成后继续安装服务端,安装服务端会比客户端更麻烦一些。
首先需要了解模拟器(手机)的CPU架构,我们可以通过ADB工具完成:
1 2 | PS C:\Users\Administrator> adb shell getprop ro.product.cpu.abi x86_64 |
然后根据结果,到Github下载对应的frida服务端二进制程序:
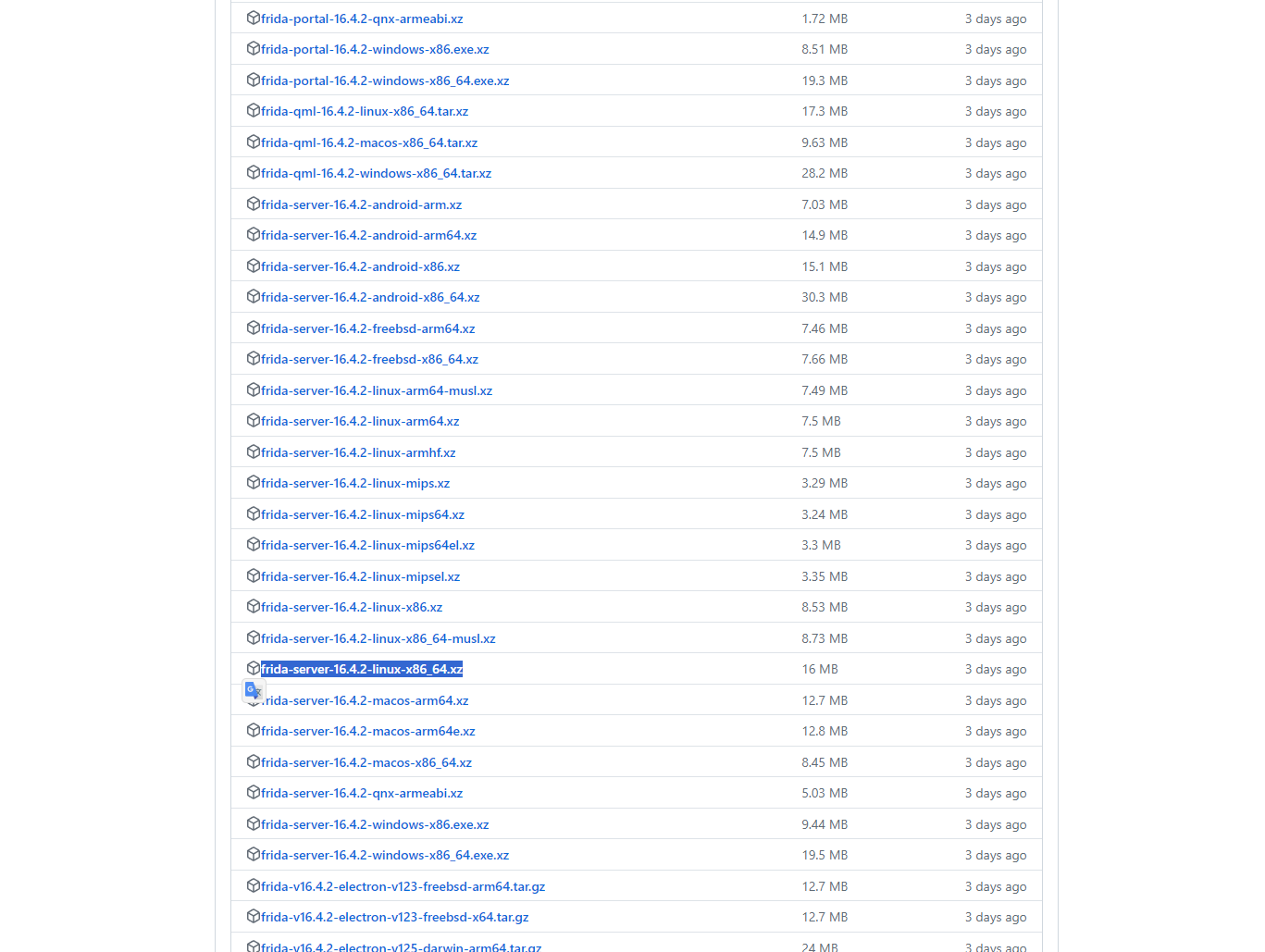
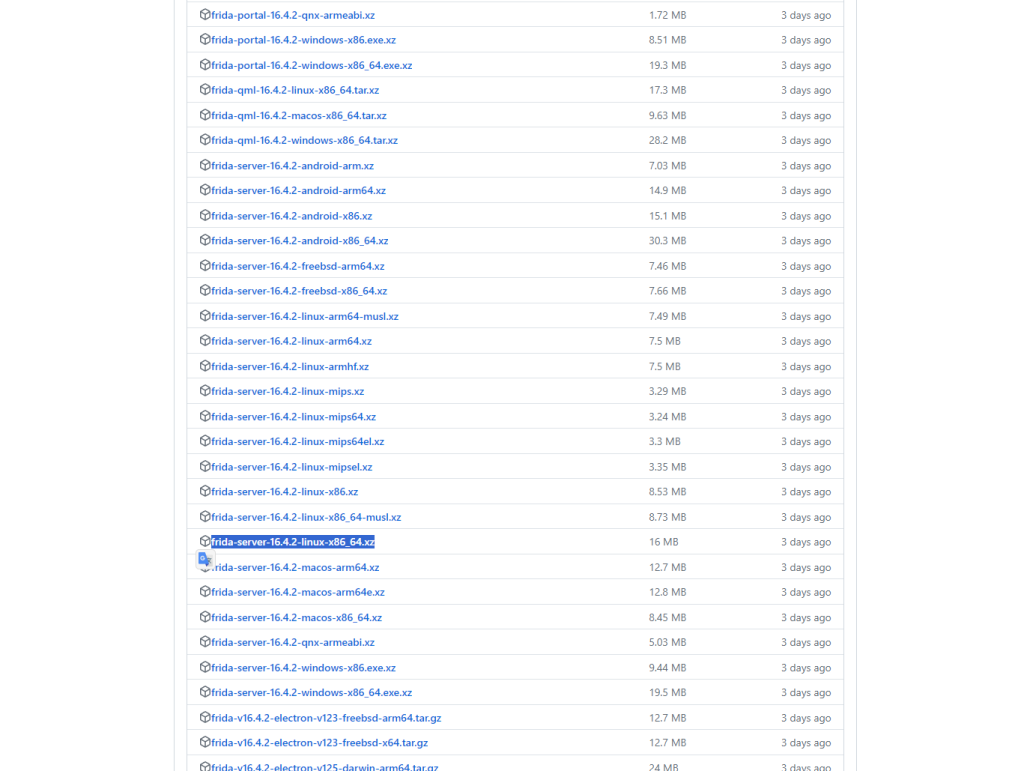
Releases中文件比较多,需要找frida-server-*开头的文件,这些是服务端文件,因为是需要在安卓系统中安装,所以选择linux平台。将文件下载下来后解压到工作项目文件夹内,并重命名为frida-server。然后在frida-server文件所在目录打开powershell,并使用ADB将frida-server推送到模拟器中:
1 | PS E:\reverse\twitter>adb push frida-server /data/local/tmp |
然后将文件权限修改为777(实际上755应该就够了):
1 | PS E:\reverse\twitter>adb shell chmod 777 /data/local/tmp/frida-server |
然后以同样的方法,将抓包工具的证书文件15推送(或复制16)到与frida-server相同的目录下。
开始调试
完成以上准备工作后,就可以正式开始进行调试工作了。
首先,为了解决抓包工具一节中提到的SSL固定问题,我们需要使用frida进行代码注入,首先通过ADB启动frida服务端。打开一个powershell窗口,确认模拟器已经连接到ADB,然后输入执行如下命令:
1 2 3 | PS C:\Users\Administrator> adb root restarting adbd as root PS C:\Users\Administrator> adb shell "/data/local/tmp/frida-server &" |
正常来说,执行完这一步操作后命令行就不会有任何响应了,此时frida-server已经启动,命令行不能关闭。
如果在执行上述命令后提示“adb.exe: no devices/emulators found”说明ADB连接模拟器失败,需要先执行 adb kill-server 关闭adb服务,然后重新执行 adb devices 或 adb connect 模拟器IP:PORT 来重新连接,重连完成后再执行上述命令启动frida服务。
编写注入脚本
这一步骤是整个流程的难点之一,我们需要编写脚本来绕过SSL固定,并使用我们自己的抓包工具的证书进行流量数据解密。
我们需要通过脚本来解决固定问题,就需要知道SSL Pinning的验证流程是怎样的。根据前面的介绍我们可以知道,SSL的验证流程大概是:建立SSL/TLS连接->服务器发送证书链->证书验证->建立安全连接。根据SSL Pinning原理我们可以知道,问题就出在证书验证这一步,有SSL Pinning技术的APP在验证证书时,除了向信任管理器进行验证,还会对比APK内保存的证书信息,所以我们可以通过重载SSL验证相关的代码逻辑,让APP用于验证的证书替换成我们自己的证书,那么验证就可以通过了。
所以需要注入的代码的大概设计思路就是:加载抓包软件的CA证书->准备包含自定义CA的KeyStore17->准备一个证书信任管理器(TrustManager)->重写SSLContext.init(Java安全套接字协议类初始化),下面,我们就按照这个顺序来进行脚本的开发。
我们可以创建一个文件,名为twitter_reverse.js,然后,我们需要确保确保脚本在 Java 虚拟机context中运行,以便使用frida的Java API,构建代码框架如下:
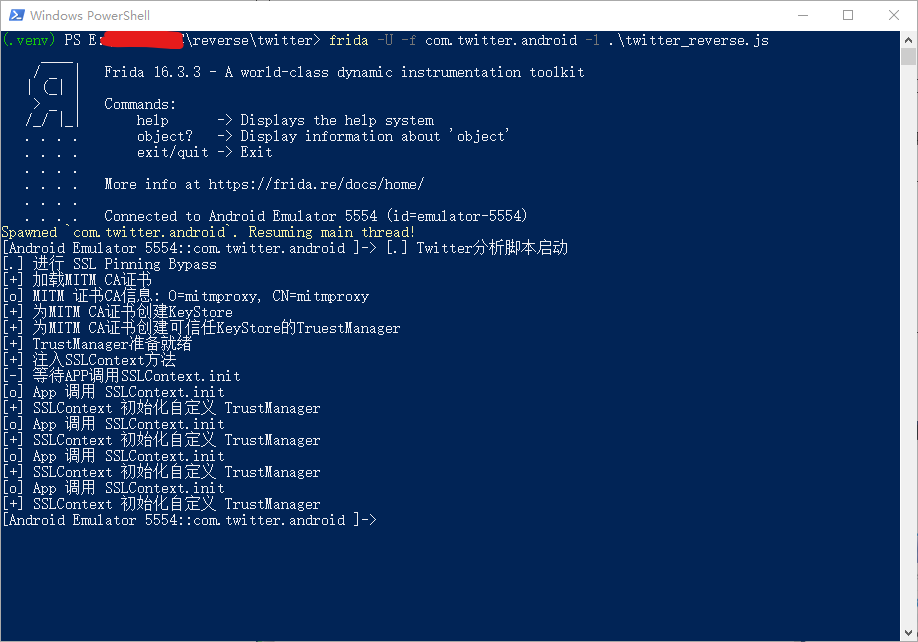
1 2 3 4 5 6 | setTimeout(function () { Java.perform(function () { console.log("[.] Twitter分析脚本启动"); // 具体代码逻辑 }); }, 0); |
这样,我们在将这段代码运行后,frida会在Powershell中打印“[.] Twitter分析脚本启动”的字符串。
随后,我们需要准备一些后面会用上的类,比如证书工厂、文件流、可信管理器、KeyStore等,代码如下:
1 2 3 4 5 6 7 8 | /* 创建证书相关类 */ var CertificateFactory = Java.use("java.security.cert.CertificateFactory"); var FileInputStream = Java.use("java.io.FileInputStream"); var BufferedInputStream = Java.use("java.io.BufferedInputStream"); var X509Certificate = Java.use("java.security.cert.X509Certificate"); var KeyStore = Java.use("java.security.KeyStore"); var TrustManagerFactory = Java.use("javax.net.ssl.TrustManagerFactory"); var SSLContext = Java.use("javax.net.ssl.SSLContext"); |
Java.use 方法是frida用于加载 Java 类的API,详细可以查看frida的官方文档的Javascript API的Java部分。
然后我们需要导入抓包工具的证书:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | /* 载入证书文件 */ console.log("[+] 加载MITM CA证书") var cf = CertificateFactory.getInstance("X.509"); try { var fileInputStream = FileInputStream.$new("/data/local/tmp/mitmproxy-ca-cert.crt"); } catch (err) { console.log("[o] 发生错误: " + err); } var bufferedInputStream = BufferedInputStream.$new(fileInputStream); var ca = cf.generateCertificate(bufferedInputStream); bufferedInputStream.close(); var certInfo = Java.cast(ca, X509Certificate); console.log("[o] MITM 证书信息: " + certInfo.getSubjectDN()); |
这段代码首先创建了一个CertificateFactory实例,该实例用于从文件中生成证书对象。然后通过文件输入 /data/local/tmp/mitmproxy-ca-cert.crt 读取抓包工具的证书文件,并使用BufferedInputStream和CertificateFactory生成X509Certificate对象。最后将生成的证书对象转换为X509Certificate,并输出证书的主体信息。
接下来创建和初始化KeyStore该KeyStore将用于初始化我们的可信管理器,代码如下:
1 2 3 4 5 6 | // 创建KeyStore console.log("[+] 为MITM CA证书创建KeyStore"); var keyStoreType = KeyStore.getDefaultType(); var keyStore = KeyStore.getInstance(keyStoreType); keyStore.load(null, null); keyStore.setCertificateEntry("ca", ca); |
创建和初始化可信管理器,并将上一步创建的KeyStore加入创建的可信管理器,代码如下:
1 2 3 4 5 6 | // 创建TrustManager console.log("[+] 为MITM CA证书创建可信任KeyStore的TruestManager"); var tmfAlgorithm = TrustManagerFactory.getDefaultAlgorithm(); var tmf = TrustManagerFactory.getInstance(tmfAlgorithm); tmf.init(keyStore); console.log("[+] TrustManager准备就绪"); |
最后重写SSLContext.init,使用我们自己的可信管理器来对SSLContext进行初始化:
1 2 3 4 5 6 7 8 | console.log("[+] 注入SSLContext方法") console.log("[-] 等待APP调用SSLContext.init") SSLContext.init.overload("[Ljavax.net.ssl.KeyManager;", "[Ljavax.net.ssl.TrustManager;", "java.security.SecureRandom").implementation = function (a, b, c) { console.log("[o] App 调用 SSLContext.init"); SSLContext.init.overload("[Ljavax.net.ssl.KeyManager;", "[Ljavax.net.ssl.TrustManager;", "java.security.SecureRandom").call(this, a, tmf.getTrustManagers(), c); console.log("[+] SSLContext 初始化自定义 TrustManager"); } |
上面就是完整的绕过SSL固定的代码,我们将这些代码保存到twitter_reverse.js,然后使用以下命令启动frida客户端:
1 | (.venv) PS E:\reverse\twitter> frida -U -f com.twitter.android -l .\twitter_reverse.js |
运行这段代码后,会在模拟器中自动启动X APP,然后我们就可以看到命令行输出的内容:
此时我们再看mitmproxy,就可以看到抓包的内容了:
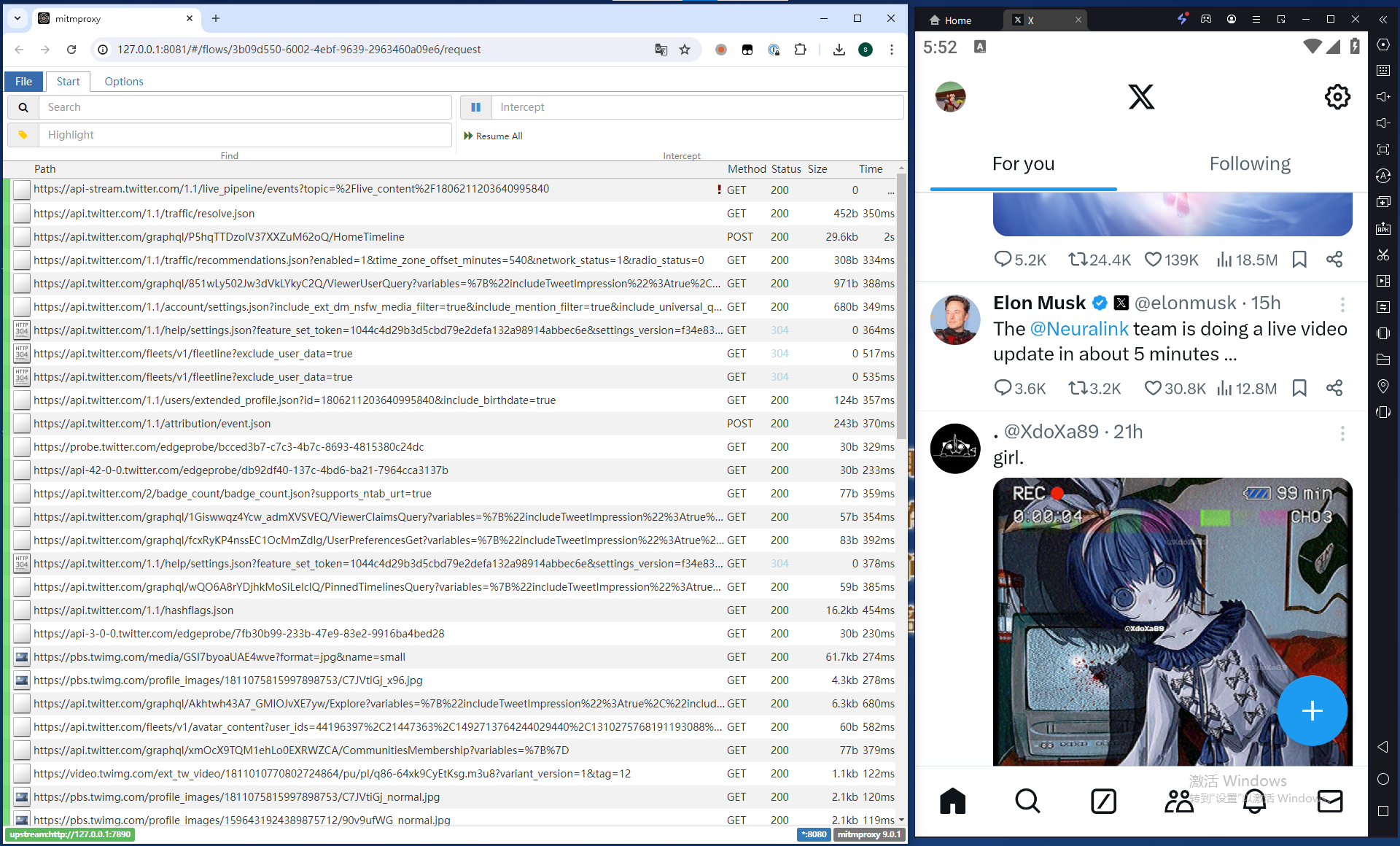
接下来,我们以采集用户(Elon Musk)基本信息为例,继续对数据进行分析。
请求流量分析
清空mitmweb中没用的数据,然后点进马斯克的主页,可以看到一条请求:


这条请求就是用于获取用户基本信息的,其返回的数据结构如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 | { "data": { "user_result": { "result": { "__typename": "User", "rest_id": "44196397", "is_blue_verified": true, "profile_image_shape": "Circle", "affiliates_highlighted_label": { "label": { "url": { "urlType": "DeepLink", "url": "https://twitter.com/X" }, "badge": { "url": "https://pbs.twimg.com/profile_images/1683899100922511378/5lY42eHs_bigger.jpg" }, "userLabelType": "BusinessLabel", "userLabelDisplayType": "Badge", "description": "X" } }, "legacy": { "can_dm": false, "can_media_tag": false, "advertiser_account_service_levels": [ "smb" ], "advertiser_account_type": "promotable_user", "analytics_type": "enabled", "created_at": "Tue Jun 02 20:12:29 +0000 2009", "description": "", "entities": { "description": { "hashtags": [], "symbols": [], "urls": [], "user_mentions": [] } }, "fast_followers_count": 0, "favourites_count": 59542, "followers_count": 189497760, "friends_count": 651, "geo_enabled": false, "has_custom_timelines": true, "has_extended_profile": true, "id_str": "44196397", "is_translator": false, "location": "", "media_count": 2288, "name": "Elon Musk", "normal_followers_count": 189497760, "pinned_tweet_ids_str": [], "profile_background_color": "C0DEED", "profile_banner_url": "https://pbs.twimg.com/profile_banners/44196397/1690621312", "profile_image_url_https": "https://pbs.twimg.com/profile_images/1780044485541699584/p78MCn3B_normal.jpg", "profile_interstitial_type": "", "profile_link_color": "0084B4", "protected": false, "screen_name": "elonmusk", "statuses_count": 46837, "translator_type_enum": "None", "verified": false, "withheld_in_countries": [] }, "super_follow_eligible": true, "super_followed_by": false, "super_following": false, "private_super_following": false, "exclusive_tweet_following": false, "smart_blocked_by": false, "smart_blocking": false, "professional": { "professional_type": "Creator", "category": [], "quick_promote_eligibility": { "is_eligible": false } }, "highlights_info": { "highlighted_tweets": "260", "can_highlight_tweets": true }, "creator_subscriptions_count": 151, "has_hidden_likes_on_profile": true, "has_hidden_subscriptions_on_profile": false, "business_account": {}, "user_seed_tweet_count": 0, "reply_device_following_v2": false, "is_profile_translatable": false, "tipjar": {} } } } } |
我们需要尝试使用Python对请求进行复现,首先,我们导出一份完整的请求,这是我们这一次的请求18:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | GET https://api-3-0-0.twitter.com/graphql/cIgulFxDKXxDxIkVedqwzQ/UserResultByIdQuery?variables=%7B%22include_smart_block%22%3Atrue%2C%22includeTweetImpression%22%3Atrue%2C%22include_profile_info%22%3Atrue%2C%22includeTranslatableProfile%22%3Atrue%2C%22includeHasBirdwatchNotes%22%3Afalse%2C%22include_tipjar%22%3Atrue%2C%22includeEditPerspective%22%3Afalse%2C%22include_reply_device_follow%22%3Atrue%2C%22includeEditControl%22%3Atrue%2C%22include_verified_phone_status%22%3Afalse%2C%22rest_id%22%3A%2244196397%22%7D&features=%7B%22verified_phone_label_enabled%22%3Afalse%2C%22super_follow_badge_privacy_enabled%22%3Atrue%2C%22subscriptions_verification_info_enabled%22%3Atrue%2C%22super_follow_user_api_enabled%22%3Atrue%2C%22blue_business_profile_image_shape_enabled%22%3Atrue%2C%22immersive_video_status_linkable_timestamps%22%3Atrue%2C%22super_follow_exclusive_tweet_notifications_enabled%22%3Atrue%7D HTTP/2.0 timezone: Asia/Tokyo os-security-patch-level: 2019-07-05 optimize-body: true accept: application/json x-twitter-client: TwitterAndroid x-attest-token: no_token user-agent: TwitterAndroid/10.47.0-release.0 (310470000-r-0) SM-S906N/9 (samsung;SM-S906N;samsung;SM-S906N;0;;1;2015) x-twitter-client-adid: 708dac85-2841-****-****-e7ccd0d47912 accept-encoding: br, gzip, deflate x-twitter-client-language: en-US x-client-uuid: af4ea391-f88f-****-****-4764122a07fe x-twitter-client-deviceid: bf015943897d**** authorization: OAuth realm="http://api.twitter.com/", oauth_version="1.0", oauth_token="18062112036********-********yD1AMIBdUNv0QRDT6iEVs", oauth_nonce="281355687661718672006782385395119", oauth_timestamp="1720688485", oauth_signature="********VR6sKIOGJ921YImQ7KQ%3D", oauth_consumer_key="3nVuSoBZnx6U4vzUxf5w", oauth_signature_method="HMAC-SHA1" x-twitter-client-version: 10.47.0-release.0 cache-control: no-store x-twitter-active-user: yes x-twitter-api-version: 5 kdt: ********BHILlfTP7zqkK8jq1MCGftWs******** x-twitter-client-limit-ad-tracking: 0 x-b3-traceid: 98724f161fab**** accept-language: en-US x-twitter-client-flavor: cookie: guest_id_marketing=v1%3A172068784430292541; guest_id_ads=v1%3A172068784430292541; personalization_id=v1_U3GKiHYNdLlBjFu7iaLhuA==; guest_id=v1%3A172068784430292541 content-length: 0 |
我们再刷新几次,多观察几个相同接口的请求,我们会发现,有4个地方每次请求都有一些数据发生了变化:
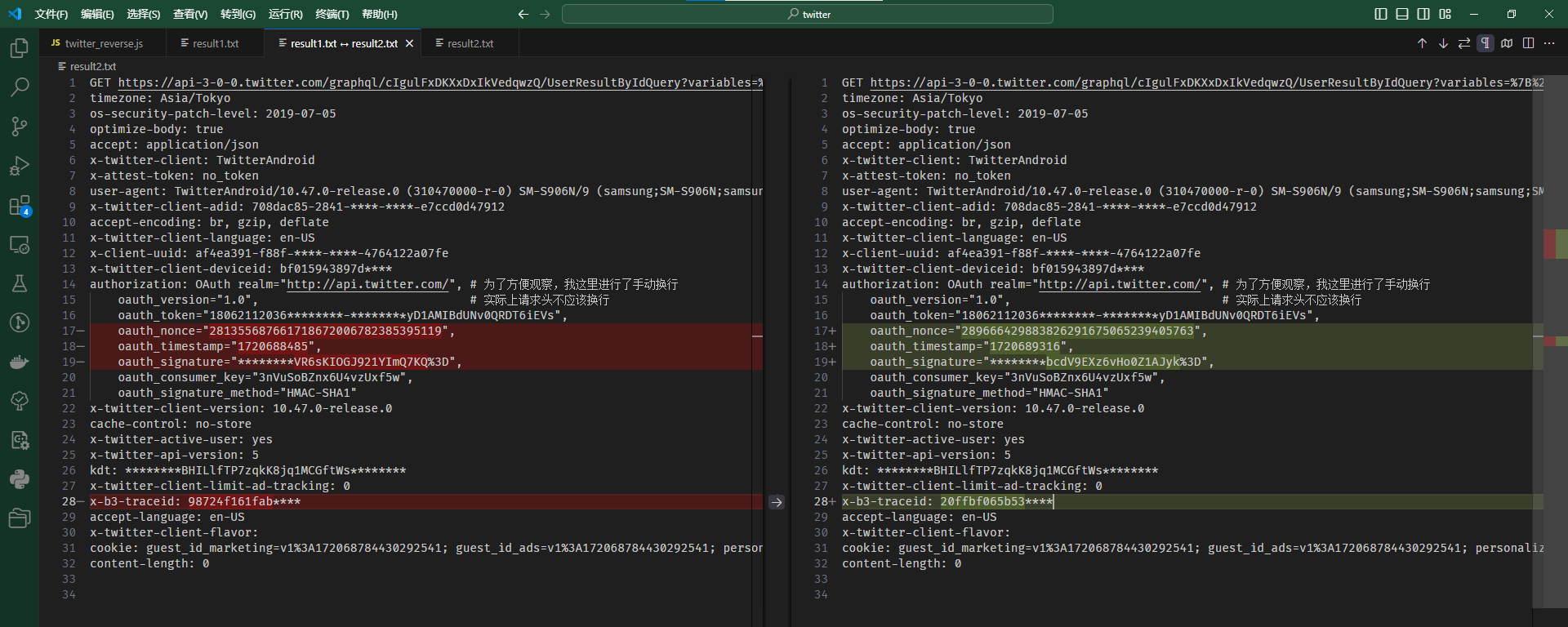
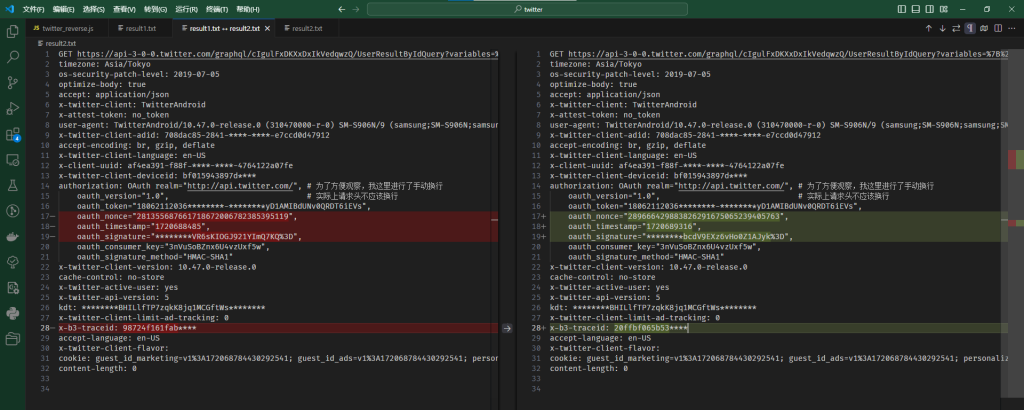
为了能够稳定地进行数据采集,防止服务器对账号进行风控,我们需要找出这四个变化的值是怎么来的。首先观察headers的key,分别为authorization和x-b3-traceid。顾名思义,authorization是用于请求的权限认证的,所以大多与账号权限有关;而x-b3-traceid是一个被广泛使用的headers,一般用于分布式系统中跟踪数据的流动,一般来说每个请求都应该有一个单独的X-B3-TraceId,所以我们只需要随机生成一个16个字符的16进制数即可。在python中,可以直接使用uuid进行生成:
1 | uuid.uuid4().hex[:16] |
比较困难的是authorization的部分,我们观察其中的几个字段,有一个字段名为oauth_signature,看名字猜测与签名有关,应该是通过其他几个改变或不变的数据进行某种算法的加密,最后得到的签名,从结果上来看,最后应该还进行了一次base64加密。
通过查看X的开发者文档,验证了我们的猜想。获得oauth_signature签名的方法为:获取请求方法和url->获取请求参数(POST请求则是获取body)->获取所有oauth_*参数,最后将这些值按照以下规则构建字符串:
内容来自X开发者文档
1. 对要签名的每个密钥和值进行百分比编码。
2. 按已编码的密钥 [2] 根据字母顺序对参数列表进行排序 [1]。
3. 对于每个密钥/值对:
4. 将已编码的密钥附加到输出字符串。
5. 将“=”字符附加到输出字符串。
6. 将已编码的值附加到输出字符串。
7. 如果还有更多的密钥/值对,则将“&”字符附加到输出字符串。
最后将请求方法、url以及最后构建的字符串连接成一段用于加密的Base String,在创建Base String时,需要满足以下规则:
内容来自X开发者文档
1. 将 HTTP 方法转换为大写字母,并将输出字符串设置为等于此值。
2. 将“&”字符附加到输出字符串。
3. 对 URL 进行百分比编码,并将其附加到输出字符串。
4. 将“&”字符附加到输出字符串。
5. 对参数字符串进行百分比编码,并将其附加到输出字符串。
完成Base String构建后,我们需要构建签名密钥,其生成方式为将Consumer secret和OAuth token secret以&符号进行连接,最后将连接的字符串作为密钥,对Base String进行HMAC-SHA1哈希运算,然后将运算结果的字节码进行base64编码,最后得到签名字符串。
根据上述流程整理一下所需的字符串,除开所有固定的字符串以外,我们还需要oauth_nonce、oauth_timestamp、oauth_token_secret、oauth_consumer_secret。在这几个值中,经过观察不难发现timestamp是10位整数时间戳,nonce是33位0-9组成的随机字符串,而oauth_token_secret和oauth_consumer_secret这两个值就不太能观察得出来了。
从oauth_token_secret的名字来看,我们可以知道,该值应该是跟token有关,既然跟token有关,那么要么是通过token计算得到,要么是在登录时由服务器返回。实际上,经过我的测试,这个值缺时是会在登录时由服务器返回,因为登录过程比较麻烦,我就不再重新进行登录了。具体是在onboarding接口的第5个阶段19(也就是登录任务完成的阶段),由服务器返回,该阶段返回的数据结构如下(部分信息已打码):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | { "flow_token": "g;263945771022****:-172057640****:DaruW6Jrnh2BIIxUq5Qa****:13", "status": "success", "subtasks": [ { "subtask_id": "LoginSuccessSubtask", "open_account": { "user": { "id": 18062112036********, "id_str": "18062112036********", "name": "Laurette ****", "screen_name": "Laurette******" }, "next_link": { "link_type": "subtask", "link_id": "next_link", "subtask_id": "SuccessExit" }, "oauth_token": "18062112036********-********qyD1AMIBdUNv0QRDT6iEVs", "oauth_token_secret": "fF4FKcL3UiSeZxFGXI4KglIjWbBSIjpJVV1DE********", "known_device_token": "0mNcn7puBHILlfTP7zqkK8jq1MCGftWs********", "attribution_event": "login" } }, { "subtask_id": "SuccessExit", "open_link": { "link": { "link_type": "subtask", "link_id": "next_link", "subtask_id": "LoginOpenHomeTimeline" } } }, { "subtask_id": "LoginOpenHomeTimeline", "open_home_timeline": { "next_link": { "link_type": "abort", "link_id": "next_link" } } } ] } |
不过不用担心,我们知道这两个值都是用于签名字符串生成的密钥,所以我们只需要想办法通过一些手段获得这个密钥即可,在获取到oauth_consumer_secret的同时还可以验证一下我们获取到的oauth_token_secret。
当然,我们可以通过反编译的方法,将APK文件进行反编译,甚至是通过打断点、dump内存等方法进行动态debug,然后检查生成authorization相关部分源代码的逻辑,最后判断APP是从哪里获取这两个值的。
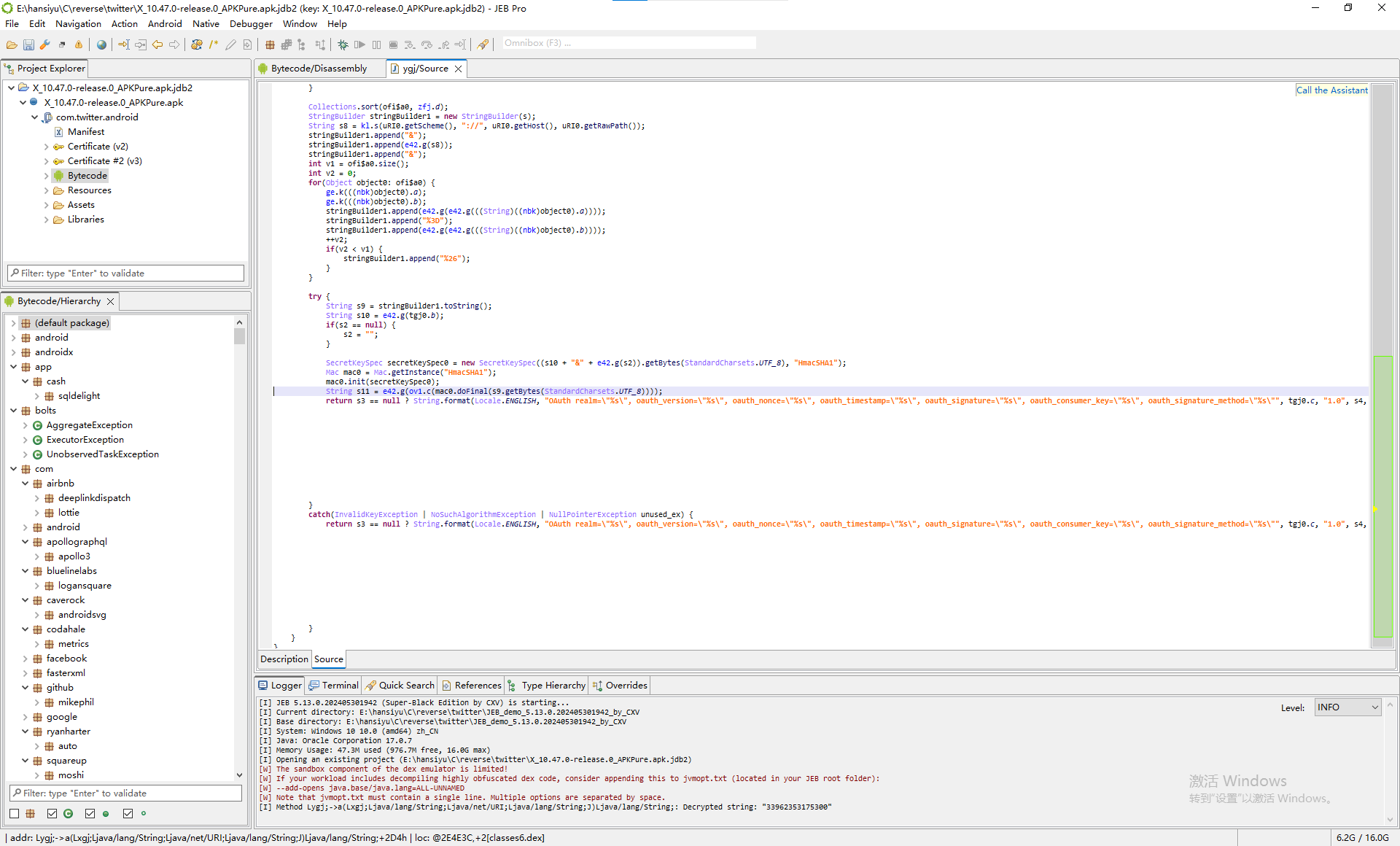
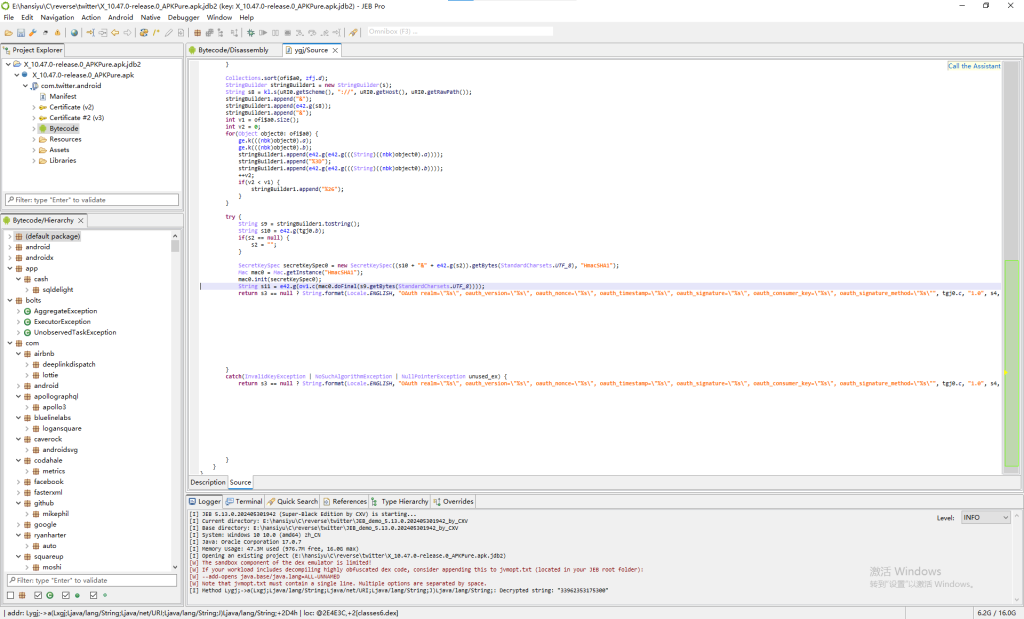
不过这种方法难度较高,等后面有空可以单独开一篇文章来研究研究安卓APK的反编译。这次我们使用更简单一点的方法。
我们在前面通过frida,重写了SSLContext.init方法,以此让APP信任抓包工具的证书,现在我们也可以使用同样的思路,重写Java中HMAC-SHA1加密的方法,在进行加密之前把Base String和密钥,以及加密后的结果打印出来,最后,我们就可以从密钥中分析得到oauth_consumer_secret。
为了实现这一功能,我们继续修改twitter_reverse.js,加入如下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | //#region HMAC-SHA1加密算法监听 console.log("[+] 监听HMAC-SHA1加密算法:") var Mac = Java.use('javax.crypto.Mac'); var SecretKeySpec = Java.use('javax.crypto.spec.SecretKeySpec') Mac.getInstance.overload('java.lang.String').implementation = function(algorithm) { console.log("[o] 正在使用算法: " + algorithm); return this.getInstance(algorithm); }; SecretKeySpec.$init.overload('[B', 'java.lang.String').implementation = function(key, spec) { console.log("[o] 检测到密钥: " + bin2hex(key) + " | " + bin2ascii(key)); return this.$init(key, spec); }; Mac.doFinal.overload('[B').implementation = function(input) { console.log("[o] 检测到Base String: " + bin2ascii(input)); var result = this.doFinal(input); var Base64 = Java.use('java.util.Base64'); var encoder = Base64.getEncoder(); var result_base64 = encoder.encodeToString(result); console.log("[o] 生成的签名: " + result_base64); return result; }; //#endregion |
Java中进行HMAC-SHA1加密需要使用javax.crypto.Mac和javax.crypto.spec.SecretKeySpec类,其中javax.crypto.Mac用于进行Mac加密,javax.crypto.spec.SecretKeySpec用于构造一个密钥规范,将原始密钥数据转换为SecretKey对象,所以我们可以通过重写Mac.getInstance捕获正在使用的算法,通过重写SecretKeySpec构造函数捕获需要构造的密钥,通过重写Mac.doFinal来观察加密的过程。
在这段程序中,还用到了两个工具函数,分别是bin2hex和bin2ascii,这两个函数将二进制字节码转换成可读的hex(16进制数)或ASCII编码,其实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | //#region 通用工具 function bin2ascii(array) { var result = []; for (var i = 0; i < array.length; ++i) { result.push(String.fromCharCode( // hex2ascii part parseInt( ('0' + (array[i] & 0xFF).toString(16)).slice(-2), // binary2hex part 16 ) )); } return result.join(''); } function bin2hex(array, length) { var result = ""; length = length || array.length; for (var i = 0; i < length; ++i) { result += ('0' + (array[i] & 0xFF).toString(16)).slice(-2); } return result; } //#endregion |
现在,我们重新执行 frida -U -f com.twitter.android -l .\twitter_reverse.js 然后进行请求,尝试捕获加密的过程,powershell输出如下:
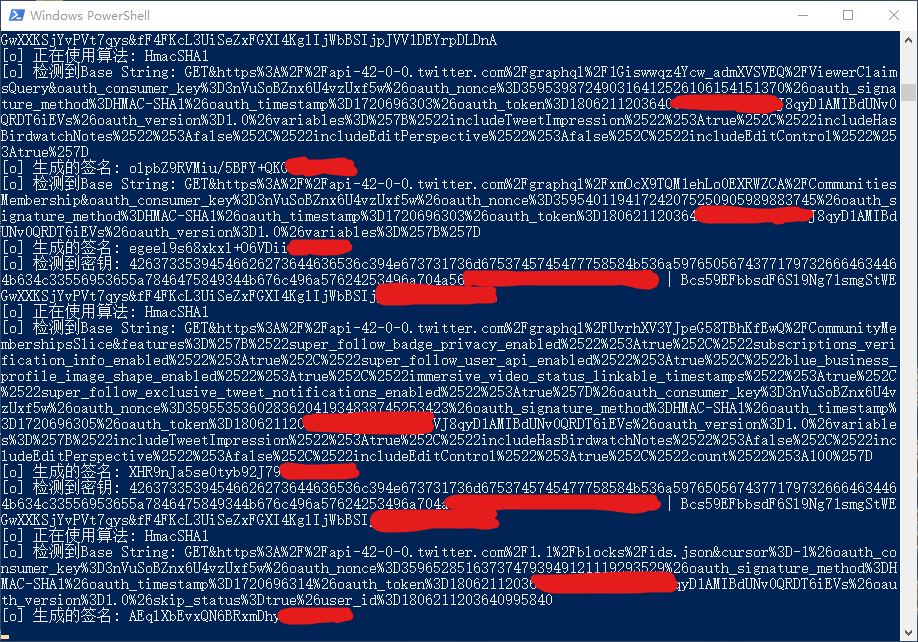
其中密钥为Bcs59EFbbsdF6Sl9Ng71smgStWEGwXXKSjYvPVt7qys&fF4FKcL3UiSeZxFGXI4KglIjWbBSIjpJVV1DE********,则OAuth token secret为fF4FKcL3UiSeZxFGXI4KglIjWbBSIjpJVV1DE********,Consumer secret为Bcs59EFbbsdF6Sl9Ng71smgStWEGwXXKSjYvPVt7qys,其中OAuth token secret与我们之前得到的数据一致。
这样我们就得到了构造请求所需的所有数据,接下来我们需要通过Python编写代码来完成生成签名的程序,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 | # auth.py def generate_oauth_nonce(): """生成 OAuth 随机数 """ return ''.join(random.choices('0123456789', k=33)) # 生成 OAuth 授权头函数 def get_oauth_authorization(oauth_token, oauth_token_secret, method='GET', url='', body='', timestamp=None, oauth_nonce=None): if not url: return '' method = method.upper() parsed_url = urllib.parse.urlparse(url) link = f"{parsed_url.scheme}://{parsed_url.netloc}{parsed_url.path}" oauth_nonce = oauth_nonce or generate_oauth_nonce() timestamp = str(timestamp or int(time.time())) # 处理 URL 参数 payload = urllib.parse.parse_qsl(parsed_url.query) # 处理请求体 if body: try: # 尝试解析为 JSON is_json = bool(json.loads(body)) except ValueError: # 如果不是 JSON,解析为查询参数 payload += urllib.parse.parse_qsl(body) # 添加 OAuth 参数 payload += [ ('oauth_version', '1.0'), ('oauth_signature_method', 'HMAC-SHA1'), ('oauth_consumer_key', TW_CONSUMER_KEY), ('oauth_token', oauth_token), ('oauth_nonce', oauth_nonce), ('oauth_timestamp', timestamp) ] # 生成签名基础字符串 payload.sort(key=lambda x: x[0]) param_str = urllib.parse.urlencode(payload, quote_via=urllib.parse.quote) param_str = param_str.replace('+', '%20').replace('%', '%25').replace('=', '%3D').replace('&', '%26') base_string = f"{method}&{urllib.parse.quote(link, safe='')}&{param_str}" # 生成签名 signing_key = f"{TW_CONSUMER_SECRET}&{oauth_token_secret or ''}" hashed = hmac.new(signing_key.encode('utf-8'), base_string.encode('utf-8'), hashlib.sha1) signature = base64.b64encode(hashed.digest()).decode('utf-8') return { 'method': method, 'url': url, 'parse_url': parsed_url, 'timestamp': timestamp, 'oauth_nonce': oauth_nonce, 'oauth_token': oauth_token, 'oauth_token_secret': oauth_token_secret, 'oauth_consumer_key': TW_CONSUMER_KEY, 'oauth_consumer_secret': TW_CONSUMER_SECRET, 'payload': payload, 'sign': signature } |
这段Python代码接收所需参数,返回一个dict值,该值中包含了构造authorization所需的值,对上面的代码使用之前请求基本用户信息的请求参数中的timestamp和oauth_nonce进行验证,得到相同的签名,说明整个流程都没有问题。
验证代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 | if __name__ == "__main__": variables = { "include_smart_block": True, "includeTweetImpression": True, "include_profile_info": True, "includeTranslatableProfile": True, "includeHasBirdwatchNotes": False, "include_tipjar": True, "includeEditPerspective": False, "include_reply_device_follow": True, "includeEditControl": True, "include_verified_phone_status": False, "rest_id": "44196397" } features = { "longform_notetweets_inline_media_enabled": True, "super_follow_badge_privacy_enabled": True, "longform_notetweets_rich_text_read_enabled": True, "super_follow_user_api_enabled": True, "unified_cards_ad_metadata_container_dynamic_card_content_query_enabled": True, "super_follow_tweet_api_enabled": True, "articles_api_enabled": True, "android_graphql_skip_api_media_color_palette": True, "creator_subscriptions_tweet_preview_api_enabled": True, "freedom_of_speech_not_reach_fetch_enabled": True, "tweetypie_unmention_optimization_enabled": True, "longform_notetweets_consumption_enabled": True, "subscriptions_verification_info_enabled": True, "blue_business_profile_image_shape_enabled": True, "tweet_with_visibility_results_prefer_gql_limited_actions_policy_enabled": True, "immersive_video_status_linkable_timestamps": True, "super_follow_exclusive_tweet_notifications_enabled": True } encode_variables = parse.quote(json.dumps(variables, ensure_ascii=False).replace(" ", "")).replace('/', '%2F') encode_features = parse.quote(json.dumps(features, ensure_ascii=False).replace(" ", "")).replace('/', '%2F') url = f"https://api-3-0-0.twitter.com/graphql/cIgulFxDKXxDxIkVedqwzQ/UserResultByIdQuery?variables={encode_variables}&features={encode_features}" account = { 'oauth_token': '', 'oauth_token_secret': '' } oauth_sign = get_oauth_authorization( account['oauth_token'], account['oauth_token_secret'], 'GET', url, timestamp="1720688485", oauth_nonce="281355687661718672006782385395119", ) authorization_header = f'OAuth realm="http://api.twitter.com/", oauth_version="1.0", oauth_token="{oauth_sign["oauth_token"]}", oauth_nonce="{oauth_sign["oauth_nonce"]}", oauth_timestamp="{oauth_sign["timestamp"]}", oauth_signature="{urllib.parse.quote(oauth_sign["sign"], safe="")}", oauth_consumer_key="{oauth_sign["oauth_consumer_key"]}", oauth_signature_method="HMAC-SHA1"' print(authorization_header) |
现在,我们可以通过编写requests代码来进行模拟请求了,具体请求完整代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 | # 用户基本信息 from requests import Session from urllib import parse import json import logging import datetime import urllib import time import uuid from logging.handlers import RotatingFileHandler from auth import headers, get_oauth_authorization PROXY = "" # 代理地址 ADID = "708dac85-2841-4c3e-b297-e7ccd0d47912" # 可以使用uuid.uuid4()生成,实际上在登录时可能需要通过 https://api.twitter.com/1.1/keyregistry/register 进行注册 CLIENT_UUID = "13f1a89c-eb31-4bef-9db8-451e4c1f0989" # 可以使用uuid.uuid4()生成,实际上在登录时可能需要通过 https://api.twitter.com/1.1/keyregistry/register 进行注册 DEVICE_ID = "bf015943897d8301" # 可以随意生成16位十六进制数,实际上在登录时可能需要通过 https://api.twitter.com/1.1/keyregistry/register 进行注册 OAUTH_TOKEN = "" # 登录时获得 OAUTH_TOKEN_SECERT = "" # 登录时获得 # 日志记录器 logger = logging.getLogger('user_logger') logger.setLevel(logging.DEBUG) console_handler = logging.StreamHandler() console_handler.setLevel(logging.INFO) rotating_file_handler = RotatingFileHandler(f'logs/user_{datetime.datetime.now().strftime("%y%m%d%H%M%S")}.log', maxBytes=10*1024*1024, backupCount=5, encoding='utf-8') rotating_file_handler.setLevel(logging.DEBUG) formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') console_handler.setFormatter(formatter) rotating_file_handler.setFormatter(formatter) logger.addHandler(console_handler) logger.addHandler(rotating_file_handler) def get_url(tw_id): variables = { "include_smart_block": True, "includeTweetImpression": True, "include_profile_info": True, "includeTranslatableProfile": True, "includeHasBirdwatchNotes": False, "include_tipjar": True, "includeEditPerspective": False, "include_reply_device_follow": True, "includeEditControl": True, "include_verified_phone_status": False, "rest_id": tw_id } features = { # 该特性(verified_phone_label_enabled)在APP的请求中默认是关闭的, 打开后返回值中会多一个verified_phone_status参数, 如果启用该特性对采集频率有影响, 可以尝试关闭 "verified_phone_label_enabled": True, "super_follow_badge_privacy_enabled": True, "subscriptions_verification_info_enabled": True, "super_follow_user_api_enabled": True, "blue_business_profile_image_shape_enabled": True, "immersive_video_status_linkable_timestamps": True, "super_follow_exclusive_tweet_notifications_enabled": True } encode_variables = parse.quote(json.dumps(variables, ensure_ascii=False).replace(" ", "")).replace('/', '%2F') encode_features = parse.quote(json.dumps(features, ensure_ascii=False).replace(" ", "")).replace('/', '%2F') return f"https://api.twitter.com/graphql/cIgulFxDKXxDxIkVedqwzQ/UserResultByIdQuery?variables={encode_variables}&features={encode_features}" def get_headers(oauth_token, oauth_token_secret, url): request_headers = headers.copy() oauth_sign = get_oauth_authorization(oauth_token=oauth_token, oauth_token_secret=oauth_token_secret, url=url) authorization_header = f'OAuth realm="http://api.twitter.com/", oauth_version="1.0", oauth_token="{oauth_sign["oauth_token"]}", oauth_nonce="{oauth_sign["oauth_nonce"]}", oauth_timestamp="{oauth_sign["timestamp"]}", oauth_signature="{urllib.parse.quote(oauth_sign["sign"], safe="")}", oauth_consumer_key="{oauth_sign["oauth_consumer_key"]}", oauth_signature_method="HMAC-SHA1"' request_headers.update({ "authorization": authorization_header, "x-b3-traceid": uuid.uuid4().hex[:16], "x-twitter-client-adid": ADID, "x-client-uuid": CLIENT_UUID, "x-twitter-client-deviceid": DEVICE_ID, }) return request_headers if __name__ == "__main__": # 这里输入用户ID # with open("userid.txt", "r", encoding="utf-8") as f: # targets = f.read().split(",") targets = ["44196397"] logger.info(f"共 {len(targets)} 个目标") session = Session() counter = 0 start_time = time.time() for target in targets: counter += 1 url = get_url(target) target_headers = get_headers(oauth_token=OAUTH_TOKEN, oauth_token_secret=OAUTH_TOKEN_SECERT, url=url) logger.debug(f"请求headers: \n{json.dumps(target_headers, ensure_ascii=False)}") session.headers.update(target_headers) logger.info(f"进行第 {counter} 次请求") response = session.get( url=url, proxies={ "http": PROXY, "https": PROXY } ) if counter % 100 == 0 and counter >= 100: use_time = round(time.time() - start_time, 4) logger.info(f"第 {counter - 100} 次到第 {counter} 次请求用时: {use_time}") start_time = time.time() if response.status_code != 200: logger.error(f"状态错误, 请求返回代码({response.status_code})不是200") try: logger.error(f"请求返回内容: \n{json.dumps(response.json(), ensure_ascii=False)}") except Exception as e: logger.error(f"请求返回内容: \n{response.content}") if response.status_code == 429: # 429一般是请求速率限制 exit() break logger.debug(f"响应headers: \n{json.dumps(dict(response.headers), ensure_ascii=False)}") try: response_json = response.json() except Exception as e: logger.error(f"将结果进行json转换时出现错误: {e}") logger.error(f"返回数据可能不是json格式: \n{response.content}") break if response_json.get("errors"): logger.error(f'返回数据中包含错误信息: {response_json.get("errors")}') logger.debug(json.dumps(response_json, ensure_ascii=False)) break logger.debug(json.dumps(response_json, ensure_ascii=False)) # TODO 具体数据处理的代码 logger.debug("休眠6秒") time.sleep(6) |
运行这段代码,成功请求到数据:


目标达成。
写在后面
这篇文章中所用到的技术更多属于动态调试,逆向方面的东西比较少(不过动态调试或许也是逆向的一部分?),其中整个流程比较复杂的地方就是编写frida脚本,但是只要理解了SSL固定的原理以及frida的使用方法,整个流程还是相对比较简单的。
实际上,这是我某个项目中用到的一个实际的例子,我也算是第一次遇到这种需求,边学边做的,所以写一篇文章用来进行记录,方便随时进行回顾。
本文所有的完整代码都已经上传到我的Github仓库:x_reverse。
- 参考Github项目: bilibili-API-collect。是的,我也是该项目的Contributors之一:) ↩︎
- 推荐一个开源项目:RSSHub,该项目整合了大量网站的爬虫,并支持以RSS的形式进行订阅。 ↩︎
- 某乎的RSS订阅链接为: https://www.zhihu.com/rss ↩︎
- HTTP/1.1与HTTP/2.0的格式有些许不同,现在用得比较多的是2.0 ↩︎
- 其实也不算是不支持,只是访问http站点会直接通过302状态码重定向到https站点 ↩︎
- 现在,因为有各种安全协议的防护,即便是公开网络,其安全性也有大幅度提升了,但仍需要防御如0day之类的攻击。还有就是,各种共享WIFI密码的APP都是极不安全的!!! ↩︎
- 这些随机数会用于生成会话密钥,防止重放攻击等。 ↩︎
- TLS1.3支持的身份验证和密钥交换协议有:DHE-RSA、ECDHE-RSA、DHE-ECDSA、ECDHE-ECDSA等,这些加密算法都具有前向安全性。 ↩︎
- 在TLS协议中,关闭通知(Close Notify)是一个用于安全终止连接的消息。该消息用于确保客户端和服务器在断开连接之前进行适当的通知,以防止未加密的数据泄露或数据截断。关闭通知在TLS1.3版本后被简化,但为了向后兼容性得以保留。 ↩︎
- BackTrack系统,也就是现在的kali linux的前身(
猜猜我的网名kalinote和这个有关么;)),专门用于做渗透测试和网络安全研究。 ↩︎ - 现在几乎所有路由器都有ARP保护功能了,这种攻击方式已经过时。 ↩︎
- DH的基本原理就是:假设A和B要进行安全沟通,他们自己分别有一个私钥,他们选择两个公开的信息分别作为基础数(一个很大的素数)和生成数(一个小于基础数的整数),A可以使用生成数和自己的私钥计算出一个公钥,并把这个公钥发送给B,B也用相同的方法计算出自己的公钥,并发送给A。A和B各自用对方的公钥和自己的私钥进行计算,得到一个共同的密钥。这个密钥一定是相同的,而攻击者由于缺少A和B的私钥参与运算,所以即便获得基础数和生成数以及公钥也无法计算出共享密钥。简单来说,这是一个数学问题。椭圆曲线DH是一个类似,但算法更加复杂的方法。 ↩︎
- 与普通版本的BlueStacks不同,并且截至到本文编写时,似乎只有BlueStacks支持兼容Hyper-V(?)。 ↩︎
- 这个步骤中可能需要设置Pin码。 ↩︎
- 这里的证书文件也就是我们在抓包工具一节中下载的mitmproxy-ca-cert.cer ↩︎
- 一般来说默认浏览器下载的默认位置是 /storage/emulated/0/Download/ 使用不同的浏览器有可能位置不同,通过 adb shell "cp /path/to/file /data/local/tmp/" 命令复制即可,至于具体下载到哪儿了,那你得自己想办法找。 ↩︎
- KeyStore是Java用来保存密钥对的,比如公钥和私钥。 ↩︎
- 由于某些信息可以用于账号和设备的追踪,所以部分信息我已经替换成星号(*)了 ↩︎
- X的APP登录接口地址为https://api.twitter.com/1.1/onboarding/task.json,但是登录任务由不同阶段完成,每个阶段需要进行一次请求,每个阶段的请求提交的参数内容也不同。这些阶段分别是:获取authorization值(仅用于登录阶段)->输入用户名->输入密码->账号双重验证检查->(如果需要双重验证)验证邮箱或手机号->登录任务完成->获取登录结果 ↩︎