




最近ChatGPT突然火起来了,实际上我从去年年底就一直在关注ChatGPT,最近我突发奇想,用ChatGPT搞了个QQ群机器人,并且实现了一些简单的功能。
注意: 本文有小部分内容由AI辅助创作,部分内容的真实性存疑,请自行判断。 本文会使用到一些方法绕过GFW,请在使用互联网时遵守当地的相关法律法规。
本文所介绍的Bot代码已经开源到了我的Github上。
很长一段时间没有写过新东西了,CPU也没在搞,主要是最近有点忙,其他事情比较多,所以就暂时没有花太多时间。不过实际上关于手搓CPU系列,我已经把16字节内存打出来了,甚至还自学了画板子,已经设计并制造出了KNArch的第一块板:时钟模块。甚至还已经完成了8位寄存器和ALU的加减法计算部分的电路板设计。
不过今天的主角不是CPU,而是KnoteBot(下面简称bot)。
Github的机缘巧合
我订阅了一个Github的推送服务,这个服务每天早上九点左右会发送一个邮件到我的邮箱,邮件的内容是Github给我推荐的一些优秀的项目。Github推荐的项目一般来说会根据添加Star的项目来进行分析。
我其实一直有想基于ChatGPT做一个QQ群聊天机器人,但是一直只是想法,没有落实出来,直到有一天早晨,Github给我推了AmiyaBot的项目。本来就一直想做,Github又刚好给我推了一个现成的框架,那就没有理由再不做了。
不过这篇文章讨论的重点是对ChatGPT的使用,而不是QQ机器人的实现或者QQ的协议分析,所以有关Amiyabot的实现细节就不多阐述了,感兴趣的同学可以到上面的Github链接中深入了解。
少废话,先看东西
既然是介绍功能为主,那么先来看看具体能实现哪些功能,下面是由Markdown渲染而成的使用说明图(从Markdown到最终图片,均由bot处理):


目前来说,暂时还只有这么几个功能,不过这些功能还都挺实用的,下面对这些功能稍微介绍一下。
对于bot的操作,除了处于会话中的聊天以外,全部是按照shell命令的执行方法来设计的,正如上图最下面的介绍来说,任何命令加-h都可以获得其使用方法,比如我对#会话命令使用-h或--help,结果如下:

从使用方法说明,我们就可以直到每个命令有哪些可使用的参数,每个参数的作用是什么。就比如根据上图来说,我们可以直到#会话命令目前一共有三个可选参数,第一个-h是输出使用方法,第二个-t或者--temperature是设置ChatGPT聊天的temperature值,第三个-so或者--system-order是设置ChatGPT的系统指令,这两个参数都是为设置ChatGPT而创建的,并且拥有默认值。
下面详细介绍以下使用说明图中的每个命令的用法和实现方法。
会话功能
聊天类指令中一共有四个指令,实际上这四个指令都是为了会话服务的,而这四个指令贯穿了从会话开始到结束的整个生命周期。使用#会话可以直接开启一段会话,此时就可以跟Bot谈笑风生了。
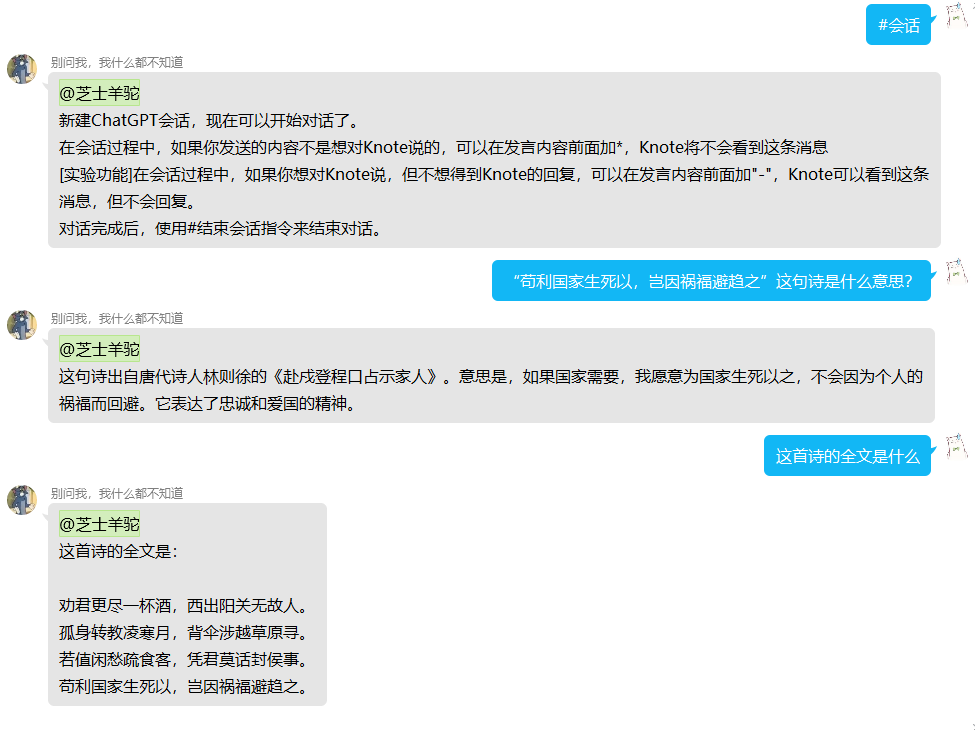
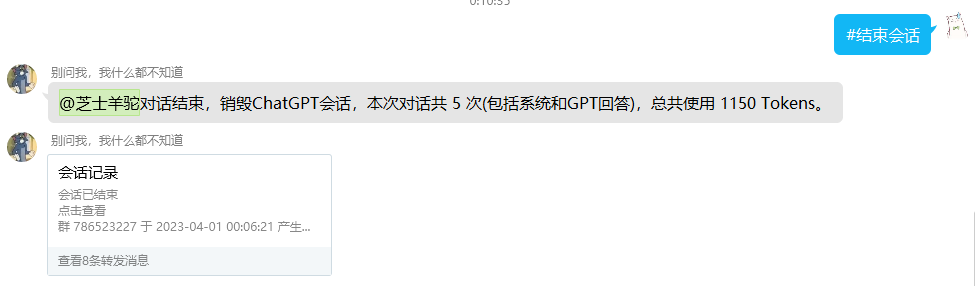
使用#结束会话指令来结束整段会话,并且Bot会将所有会话内容整合到一个聊天记录中:
另外两个指令,一个#重启会话其实就是方便重开一段会话,而不用先使用结束指令再使用开始指令这么麻烦,另一个会话历史则是在不结束会话的情况下,将所有已经进行的会话打包成类似上图的聊天记录的形式,这两条指令就不多介绍了。
下面简单介绍一下这些功能的实现方法。
上面这一系列功能都是用来实现ChatGPT对话的,其本质就是调用OpenAI给出的API接口。现阶段来说,OpenAI开放了GPT-3.5、text-davinci-002/003、code-davinci-002、以及DALL·E、Whisper等,其中GPT-3.5、text-davinci-002/003用于对话(Chat completion)及文本完善(Text completion),DALL·E用于图像生成(后面会用到),Whisper用于语言识别。还有需要申请才能使用的GPT-4,不过我暂时还没有见到过有人申请成功。
由于部分特殊原因,国内无法访问OpenAI的服务,所以我们需要使用一些手段绕过GFW(中国国家长城防火墙, Great Firewall)。我自己使用的方案是Trojan+clash,Torjan使用特征明显的TLS协议 (TLS/SSL),使得流量看起来与正常的HTTPS网站相同,所以其相较于ssr协议来说,有更高的安全性和隐匿性,其更难以被防火墙发现并查杀。而clash可以基于规则化的脚本对不同的流量进行多个代理服务器的分发。比如我同时在美国、香港、广州购买了三台VPS(我还真买了...不过不全是用于代理网络),我希望google和openai的服务从美国的VPS发出,普通的外网ip的访问流量从香港的VPS发出,国内的流量从广州的IP发出,那么我可以通过设置一个clash的规则文件,将所有google和openai的域名和ip的访问流量发送到美国的Torjan服务器,其他外网ip访问流量发送到香港的VPS,其余的走广州VPS。不过配置代理和网络并不是本文的主要内容,所以大家只需要知道,我的QQ机器人是部署在广州VPS上,并且我又在美国和香港的VPS上搭建了Torjan服务段即可。
OpenAI有官方的API接口,所以实际上直接import openai就可以很方便地调用其服务。但由于上述原因,我们在访问OpenAI的API时需要将HTTP/HTTPS的流量发送到127.0.0.1:7890(这是clash默认开发给局域网的http端口),所以我们无法直接使用openai的依赖包,而需要使用requests模块来手动发送请求。
Show me the code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 | class ChatGPT: url = 'https://api.openai.com/v1/chat/completions' def __init__(self, temperature=0.7, system_order='', set_user=False): # 准确度,0到1之间,越小准确度越高,回答也就更精确,但限制更多 self.temperature = temperature self.system_order = system_order # 是否在用户发送的对话前添加[username] self.set_user = set_user # 对话组,将所有对话保存在里面 self.conversations_group = [] if self.system_order: self.add_conversation('system', self.system_order) # 对话总token数 self.tokens_count = 0 self.next_alarm_token_counts = 30000 # 会话开始时间 self.start_time = time.time() def get_set_user(self): return self.set_user def get_start_time(self): return self.start_time def get_conversations_group(self): return self.conversations_group def get_conversations_count(self): """ 获取对话总次数 :return: """ return len(self.conversations_group) def get_tokens_count(self): return self.tokens_count def get_data(self): messages = [conversation['message'] for conversation in self.get_conversations_group()] return { "model": "gpt-3.5-turbo", "messages": messages, "temperature": self.temperature } def add_conversation(self, role, content): """ 添加对话到对话组 :param role: :param content: :return: """ self.conversations_group.append(self.gen_conversation(role, content)) @staticmethod def gen_conversation(role, content): """ 通过角色和内容生成对话 :param role: :param content: :return: """ return { "message": { "role": role, "content": content, }, # 下面是自己加的,不是ChatGPT要求的 "send_time": time.time() } def tokens_usage_check(self): """ 检查token数,并在有需要时返回值进行报警 :return: """ if self.get_tokens_count() > self.next_alarm_token_counts: self.next_alarm_token_counts += 10000 return self.get_tokens_count() return False def call(self, content): """ 将新的对话添加到对话组,并请求 :param content: :return: """ self.add_conversation('user', content) try: ret = requests.post( url=ChatGPT.url, headers=headers, data=json.dumps(self.get_data()), proxies=proxies ).text # print(ret) ret_json = json.loads(ret) except Exception as e: log.error(f"在处理ChatGPT对话时发生了错误: {e}") self.conversations_group.pop() return f"在处理ChatGPT对话时发生了错误: {e}" try: answer = ret_json['choices'][0]['message']['content'] self.tokens_count += int(ret_json['usage']['total_tokens']) except Exception as e: log.error(f"在处理json时出现错误,{e},JSON原文为:{str(ret_json)}") self.add_conversation('assistant', 'no reply') return f"[ChatGPT Handler]在处理json时出现错误,{e},JSON原文为:{str(ret_json)}" self.add_conversation('assistant', answer) return answer def restart(self): """ 重新开始对话,但保留tokens_count计数 :return: """ self.conversations_group = [] self.add_conversation('system', self.system_order) |
我使用了一个类来实现GPT各模块的操作,这样每启动一个会话,只需要实例化ChatGPT类即可,下面来深入探索一下这个类中的方法。
首先是__init__,其中定义了一些类的变量,然后这个构造函数提供了3个参数,分别是temperature、system_order和set_user。前两个都很好理解,其对应了ChatGPT的这两个参数。最后一个set_user需要单独解释一下,起初我在群聊中部署了这个机器人,对话起来很流畅,没有什么问题,但使用了一段时间以后我发现,随机机器人在QQ群里面,但是GPT却无法分清楚每条消息是哪个群成员发送的,所以我设置了这个参数,当该参数为True时,这个类在发送群成员信息时,会在消息前面加上[群昵称],只要通过系统指令告诉GPT每条消息最前面的括号里面是说这句话的群成员,GPT就能认识并分清楚每个群成员的发言。
继续往下,是一些以get_开头的方法,这些方法都是用于获取类变量使用的,没有太多需要介绍的内容。
get_data是用于构造请求体data的方法,根据openai的官方文档,我们知道使用ChatGPT进行请求时,需要根据如下格式:
1 2 3 4 5 6 7 | curl https://api.openai.com/v1/chat/completions \ -H "Content-Type: application/json" \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -d '{ "model": "gpt-3.5-turbo", "messages": [{"role": "user", "content": "Hello!"}] }' |
每次向openai发送请求时,都将调用该方法,将ChatGPT对象中存储的对话内容格式化成文档中要求的格式。
这里提到了ChatGPT对象中存储的对话,详细的说:由于ChatGPT在每次进行请求时,需要提供上下文,并且按照规定的格式,所以我需要在对象中存储这一次对话的上下文,我使用了self.conversations_group用于存储对话组。而add_conversation就是用于向对象的对话组中插入对话的方法,这个方法需要两个参数,分别是角色(role)和内容(content)。在openai给出的文档当中,我们可以知道,ChatGPT接受三个角色,分别是系统(system)、用户(user)、助手(assistant),分别用于标记系统指令、用户和ChatGPT的对话内容。gen_conversation方法就是将self.conversations_group中存储的对话组转换成API要求的格式的内容。
为了方便计算费用,我设计了tokens_usage_check方法,该方法用于监控每轮对话使用的token数,一旦token数超过了阈值,则向用户发出提醒。
最后是call方法,需要提供一个参数,该参数为用户向ChatGPT发出的内容。在该方法内,程序会将用户希望发送的内容, 以及历史会话记录整合成指定的格式,并使用requests进行请求。
这个类的原理大概就是这样,不过实际上这个方法并不完美,Amiya机器人框架全程使用异步操作await/async,而requests请求是同步的,实际上为了更好的异步执行,应该选择异步请求类。不过我在初期调用了某个异步请求类,出现了一些不太好解决的问题,所以退而求其次使用了requests。
完成ChatGPT类代码的解析后,再来了解一下会话部分指令的处理方式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 | class Meta: command = "#会话" description = "开始一段会话,每个群只能同时开启一个单独的会话(除单次会话外)" # 普通会话模式 async def start_session_verify(data: Message): return True if data.text.startswith(Meta.command) else False @bot.on_message(verify=start_session_verify, level=normal_order_level, check_prefix=False) async def start_session(data: Message): # 解析参数 parser = ArgumentParser(prog=Meta.command, description=Meta.description, exit_on_error=False) # 添加选项和参数 parser.add_argument('-t', '--temperature', type=float, default=0.7, help="ChatGPT的temperature值,为0-1之间的浮点数,该值越高(如0.8)将使输出更随机,而越低(例如0.2)将使其更集中和更确定,默认值0.7") parser.add_argument('-so', '--system-order', type=str, help="开始对话前的系统指令,用于指示该轮会话ChatGPT所扮演的角色或需要做的事,越详细越好,默认值为系统预置的普通对话系统指令") parser.add_argument('-no', '--no-order', action='store_true', help="是否不设置系统指令,如果指定该参数,则不设置任何系统指令(包括默认系统指令)") parser.add_argument('-s', '--single', action='store_true', help="是否为单句会话模式,如果指定该参数,则只进行一次问答,且不能设置系统指令(-so和--system-order参数无效)。") parser.add_argument('-p', '--prompt', type=str, default=None, help="对话提示词,在单句会话模式中使用,如果是单次会话模式(指定-s或者--single参数),则参数必须指定,否则指定该参数无效。") parser.add_argument('-u', '--user', action='store_true', help="是否在聊天前添加[username]来对用户进行区分,如果指定该参数,则添加用户名区分。在使用默认系统指令的连续会话时会自动指定,其他情况均不会自动指定。") # 解析命令 try: args = parser.do_parse(data.text) except Exception as info: # 实际上不一定是错误,-h也会触发 return Chain(data).text(info.__str__()) temperature = args.temperature no = args.no_order single = args.single prompt = args.prompt user = args.user order = args.system_order if not single: if not no: if not args.system_order: order = system_order['普通对话'] user = True else: order = args.system_order else: order = None # 先处理单句会话 if single: if prompt is None: return Chain(data).text("使用单次会话模式时(指定-s或者--single参数),必须通过-p或者--prompt参数来指定提示词。\n详细使用方法请使用-h或--help参数查询。") return Chain(data).text(ChatGPT(temperature=temperature, system_order=None, set_user=user).call(content=(f"[{data.nickname}]" if user else '') + prompt)) if gpt_sessions.get(data.channel_id, None) is not None: return Chain(data).text(f"上一次会话尚未结束,或结束后为及时清理会话,请使用"{end_session.Meta.command}"来清除当前会话,并使用"{Meta.command}"来开启一个新的ChatGPT会话。") gpt_sessions[data.channel_id] = ChatGPT(temperature=temperature, system_order=order, set_user=user) return Chain(data).text("\n\n新建ChatGPT会话,现在可以开始对话了。\n\n" f"在会话过程中,如果你发送的内容不是想对{bot_name}说的,可以在发言内容前面加*,{bot_name}将不会看到这条消息\n\n" f"[实验功能]在会话过程中,如果你想对{bot_name}说,但不想得到{bot_name}的回复,可以在发言内容前面加"-",{bot_name}可以看到这条消息,但不会回复。\n\n" f"对话完成后,使用"{end_session.Meta.command}"指令来结束对话。") |
这一段代码是#会话指令的实现,为了方便修改和生成指令文档,我给每个指令添加了一个Meta的类,该类标记了对应的指令和指令的描述,这一点我们在#使用说明指令的实现中再介绍。
其实代码的结构很简单,首先是对参数的处理,这里我继承了argparse.ArgumentParser,并按照我自己的需求进行了一些修改。因为实际上,argparse.ArgumentParser是用于shell执行时的命令解析,所以argparse.ArgumentParser在遇到一些错误时会直接退出程序,而该过程无法被异常捕捉。所以我重写了error方法,去掉了退出程序的部分,并将异常抛出交给外面一级的程序来解决,其实现代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | class ArgumentParser(argparse.ArgumentParser): def do_parse(self, command): # 帮助信息 parameters = shlex.split(command)[1:] if '-h' in parameters or '--help' in parameters: raise ThrowMessage(self.format_help()) # 解析命令 try: args = self.parse_args(args=parameters) except Exception as e: raise ThrowMessage(f"参数解析错误: {e}\n该命令使用方法如下:\n{self.format_help()}") return args def error(self, message): raise ThrowMessage(message) |
其中ThrowMessage是我自定义的一个异常,该异常仅用于抛出消息交给上级异常处理程序处理,这里就不过多介绍了。
完成参数解析后,需要针对设置的参数进行判断,比如该次会话是否为单句会话,会话是否使用预设的系统指令,是否添加用户名区分之类的,这一段逻辑很简单,没什么需要单独介绍的。
不过需要说明的是,我在ChatGPT的类文件中定义了一个gpt_sessions = dict(),每个群如果创建了一个非单次会话,就会向这个字典中进行写入操作,方便下次处理时直接使用gpt_sessions[群号码]来取到该群的会话,并进行相关处理。
接下来是会话内容的处理,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | async def gpt_verify(data: Message): # 过滤掉以*开始的消息,作为停止词 if data.text.startswith('*'): return None return True if gpt_sessions.get(data.channel_id, None) is not None else None @bot.on_message(verify=gpt_verify, level=chat_level) async def gpt(data: Message): if data.text.startswith("-"): gpt_sessions.get(data.channel_id).add_conversation('user', f"[{data.nickname}]{data.text[1:]}") return chat_gpt = gpt_sessions.get(data.channel_id) answer = chat_gpt.call((f"[{data.nickname}]" if chat_gpt.get_set_user() else '') + data.text) alarm = gpt_sessions.get(data.channel_id).tokens_usage_check() if alarm: await bot.send_message(Chain().text(f"[Alarm]当前会话已进行{gpt_sessions.get(data.channel_id).get_conversations_count()}次,Token已使用数量为: {alarm},请注意控制用量"), channel_id=data.channel_id) # 处理markdown if answer.startswith('[MD]'): return Chain(data).markdown(answer) else: return Chain(data).text(answer) |
在消息校验器中,我设置了几个判断逻辑,首先是消息是否以*开头,如果是则不处理,其次是从gpt_sessions中查询该群是否有正在进行的会话,如果没有则不处理。
在进行消息处理时,首先会判断该会话是否要求在提示词前面添加用户名区分,然后使用ChatGPT对象的call方法来获取GPT的回复。我在默认系统指令中告诉了GPTP:"如果某段话中含有markdown的内容,你需要在回答的最前面加上[MD]标识",所以如果使用默认系统指令,在GPT返回的消息中含有Markdown内容时,就会以Markdown图片的方式发送(因为QQ不支持发送格式化消息)。
其他的比如#结束会话等的指令实现起来都比较简单,就不过多介绍了。在结束会话时,将ChatGPT对象从gpt_sessions中删除即可。
搜索功能
在介绍画图功能之前,先来介绍更为简单的搜索功能,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 | def get_middle_chars(s, n): middle = len(s) // 2 start = middle - n // 2 end = start + n return s[start:end] def split_string(string, n): return [string[i:i+n] for i in range(0, len(string), n)] class Meta: command = "#搜索" description = "通过搜索引擎搜索相关内容,并通过GPT进行资料整理。" # 请求网站 async def search_verify(data: Message): return True if data.text.startswith(Meta.command) else None @bot.on_message(verify=search_verify, level=normal_order_level, check_prefix=False) async def search_website(data: Message): # 解析参数 parser = ArgumentParser(prog=Meta.command, description=Meta.description, exit_on_error=False) # 添加选项和参数 parser.add_argument('-k', '--keyword', type=str, default="kalinote.top", help="需要搜索的关键词,默认为"kalinote.top"") # 解析命令 try: args = parser.do_parse(data.text) except Exception as info: # 实际上不一定是错误,-h也会触发 return Chain(data).text(info.__str__()) keyword = args.keyword url = f"https://www.google.com/search?q={keyword}" await bot.send_message(Chain().at(data.user_id).text("[实验功能]正在请求搜索内容,由于openai限制每分钟请求数,内容较多的页面所以可能会较慢,请稍等..."), channel_id=data.channel_id) async with async_playwright() as p: browser = await p.chromium.launch( proxy={ "server": f"{PROXY_IP}:{PROXY_PORT}", "username": "", "password": "" } ) page = await browser.new_page() await page.goto(url, wait_until="load") # 定位第一个 <h3> 标签的父标签并跳转 # h3_element = await page.query_selector('h3') # parent_element = await h3_element.query_selector('xpath=..') # await page.goto(await parent_element.get_attribute('href')) # 处理机器人验证 if await page.query_selector("#rc-anchor-container"): # print("执行了处理机器人验证") await page.click("#rc-anchor-container") h3_elements = await page.query_selector_all('h3') if not h3_elements: # 页面中没有h3元素 await bot.send_message(Chain().text("出现错误,没有在google的搜索页面找到h3,请稍后或换一个关键词重试!"), channel_id=data.channel_id) # print(await page.content()) screenshot_bytes = await page.screenshot(full_page=True) return Chain(data).image(screenshot_bytes) for h3_element in h3_elements: parent_element = await h3_element.query_selector("xpath=..") if not parent_element: continue href = await parent_element.get_attribute('href') if href is not None: # 找到具有href属性的父元素 await page.goto(href) break screenshot_bytes = await page.screenshot(full_page=True) await bot.send_message(Chain().image(screenshot_bytes), channel_id=data.channel_id) # content = await page.inner_text('h1, p, div') full_content = await page.inner_text('body') content_list = split_string(full_content, 3000) count = 0 for content in content_list: count += 1 gpt = ChatGPT(temperature=0.3, system_order=system_order['网页分析助手']) await bot.send_message(Chain().text(f"第{count}/{len(content_list)}段:\n" + gpt.call(content)), channel_id=data.channel_id) time.sleep(1) return |
该功能可以通过关键词在google上进行搜索,并且进入google搜索到的第一个页面,然后将页面的内容发送给ChatGPT进行整合,最后返回整合结果,其效果如下:
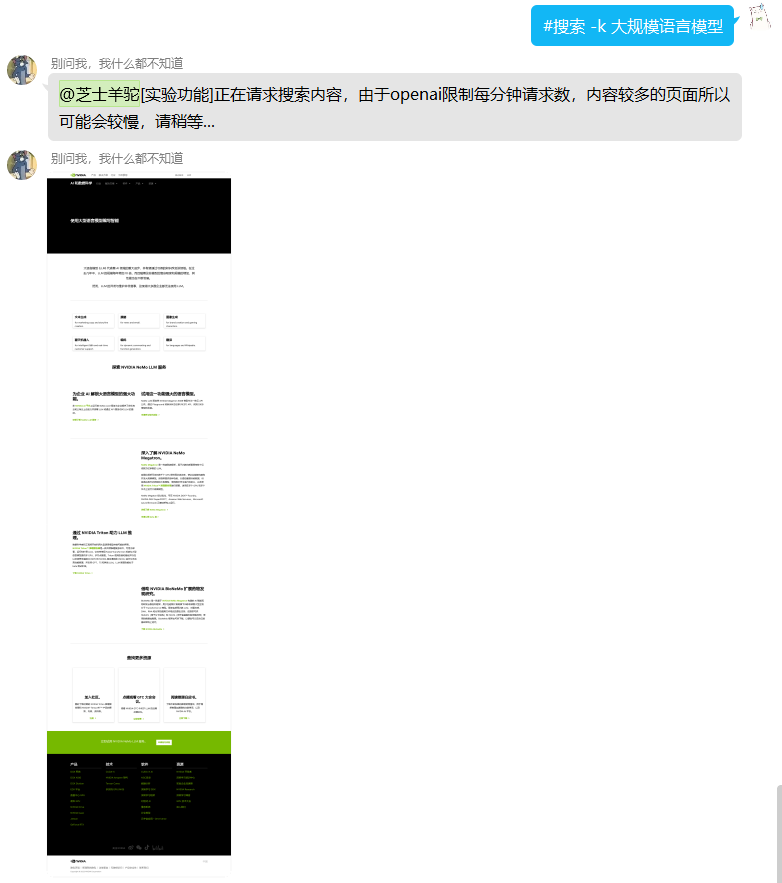
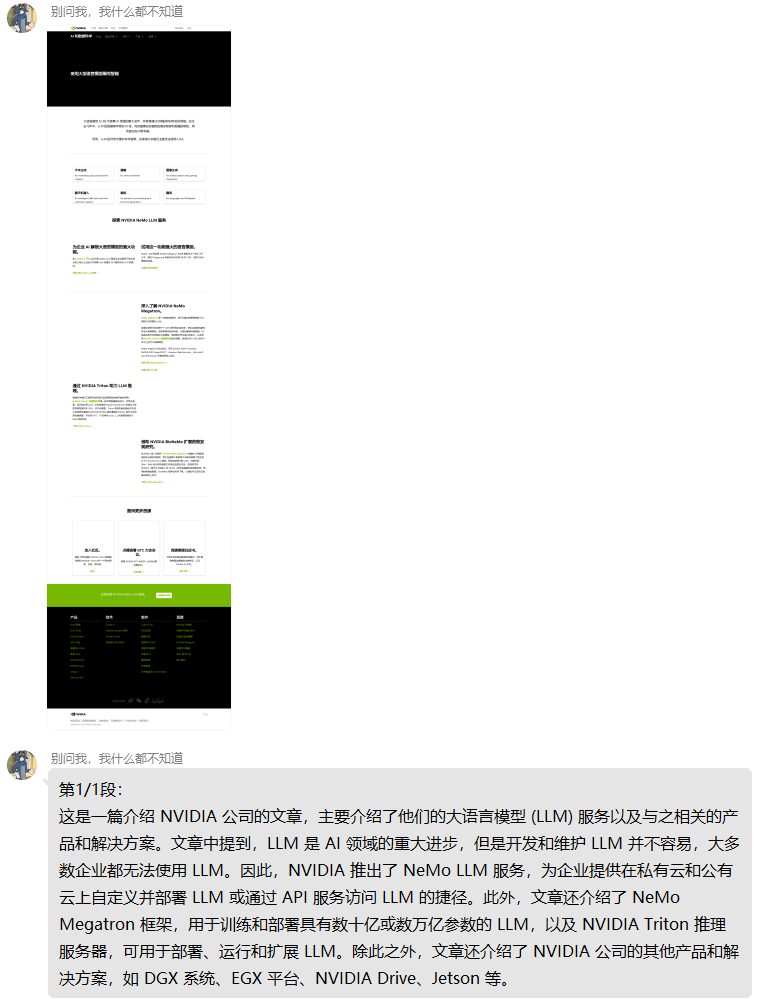
不过由于GPT-3.5模型限制最大token为4096,所以实际上如果网页的内容超过4096tokens,就会分割成多个会话进行分析,且无法关联上下文内容。
为了更加安全、方便地取到页面,我没有直接使用requests请求或其他爬虫程序,而是使用playwright模拟浏览器进行请求,使用这个方法的好处是,该行为很难被服务器检测到,因为模拟浏览器与用户直接操作没有任何差异。并且可以直接通过浏览器渲染js,简单地解决了很多网站的反爬机制的问题。playwright微软开发的开源程序,所以关于更多playwright的信息,可以在playwright的GitHub网站上找到。
这个功能在页面文字较少且排版复杂的时候比较好用,但是如果页面文字较多,则会严重影响GPT进行内容分析。不过最新的GPT-4将最大tokens提升到了32k,所以等GPT-4公开且成本降低后,应该就可以解决这个问题。
画图
画图使用的是OpenAI的DALL·E模型,我编写了一个类来实现相关操作,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 | class ImageGeneration: url = 'https://api.openai.com/v1/images/generations' def __init__(self, prompt, gen_number=1, size="1024x1024"): self.gen_number = gen_number self.size = size self.prompt = prompt self.urls = [] def get_data(self): return { "prompt": self.prompt, "n": self.gen_number, "size": self.size } def call(self): try: ret = requests.post( url=ImageGeneration.url, headers=headers, data=json.dumps(self.get_data()), proxies=proxies ).text ret_json = json.loads(ret) except Exception as e: log.error(f"在请求图片时出现了错误: {e}") return f"在请求图片时出现了错误: {e}" try: urls = [datas['url'] for datas in ret_json['data']] self.urls = urls except Exception as e: log.error(f"在解析json时出现了错误: {e}, json原文: {ret_json}") return f"[Draw Handler]在处理json时出现错误,{e},JSON原文为:{str(ret_json)}" return urls def download_images(self): if not self.urls: return False filenames = [] try: for url in self.urls: ret = requests.get(url=url, proxies=proxies) if ret.status_code != 200: del ret return False filename = str(hashlib.md5(ret.content).hexdigest()) + '.png' with open(f'{image_dir}/{filename}', 'wb') as f: f.write(ret.content) filenames.append(filename) return filenames except Exception as e: log.error(f"在下载生成的图片时发生了错误: {e}") return False |
实际上该类最主要的两个功能分别是call方法将提示词发送给服务器生成图片,然后是download_images方法,通过服务器返回的链接下载图片。
画图指令处理的基本流程就是,用户使用自然语言作为提示词,然后将提示词发送给ChatGPT让其改进为更适合DALL·E模型的提示词,最后生成图片,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | class Meta: command = "#画图" description = "通过自然语言绘制图片" # 画图(先暂时固定生成1024,1张) async def draw_verify(data: Message): return True if data.text.startswith(Meta.command) else None @bot.on_message(verify=draw_verify, level=normal_order_level, check_prefix=False) async def draw(data: Message): # 解析参数 parser = ArgumentParser(prog=Meta.command, description=Meta.description, exit_on_error=False) # 添加选项和参数 parser.add_argument('-n', '--generated-number', type=int, default=1, help="生成图片数量,一般为1-10之间的整数,不建议一次生成超过3张,数量过高出现问题的概率会增大,默认为1") parser.add_argument('-p', '--prompt', type=str, default=None, help="对需要生成的图片的描述,使用自然语言,越详细越好,虽然中文也可以,但是英文的准确度更高,此项必填") parser.add_argument('-s', '--size', type=str, default="512x512", help="生成图片的分辨率,只能为128x128、512x512、1024x1024其中之一,默认为512x512") # 解析命令 try: args = parser.do_parse(data.text) except Exception as info: # 实际上不一定是错误,-h也会触发 return Chain(data).text(info.__str__()) number = args.generated_number prompt = args.prompt size = args.size # 判断参数是否正确 if size not in ['128x128', '512x512', '1024x1024']: return Chain(data).text(f"指定的图像尺寸不正确,支持的尺寸为: 128x128、512x512、1024x1024,指定的尺寸为: {size}") if not prompt: return Chain(data).text(f"需要使用-p/--prompt参数指定prompt(对图片的描述),使用"{Meta.command} -h"查看详细帮助") if number > 10 or number < 1: return Chain(data).text(f"指定的数量不正确,数量只能为1-10之间的整数,指定的数量为: {number}") await bot.send_message(Chain().at(data.user_id).text("正在准备生成,请稍等..."), channel_id=data.channel_id) # 通过GPT将prompt处理为英文 prompt_en = ChatGPT(temperature=0, system_order=system_order['翻译助手']).call(content=prompt) image_generation = ImageGeneration(prompt=prompt_en, gen_number=number, size=size) urls = image_generation.call() if type(urls) == str: return Chain(data).text(urls) files = image_generation.download_images() if not files: return Chain(data).text("图像生成错误,请稍后重试!") image_count = 0 for file in files: with open(f'{image_dir}/{file}', 'rb') as f: image = f.read() image_count +=1 await bot.send_message(Chain().text(f'prompt: {prompt_en}, size: {size}, number: {image_count}/{len(files)}').image(image), channel_id=data.channel_id) return |
画图没有什么太多内容进行介绍,就只是简单地进行了一个接口调用,然后使用到了一些IO操作对图片进行处理,结合代码就能快速理解其逻辑。
其效果如下:
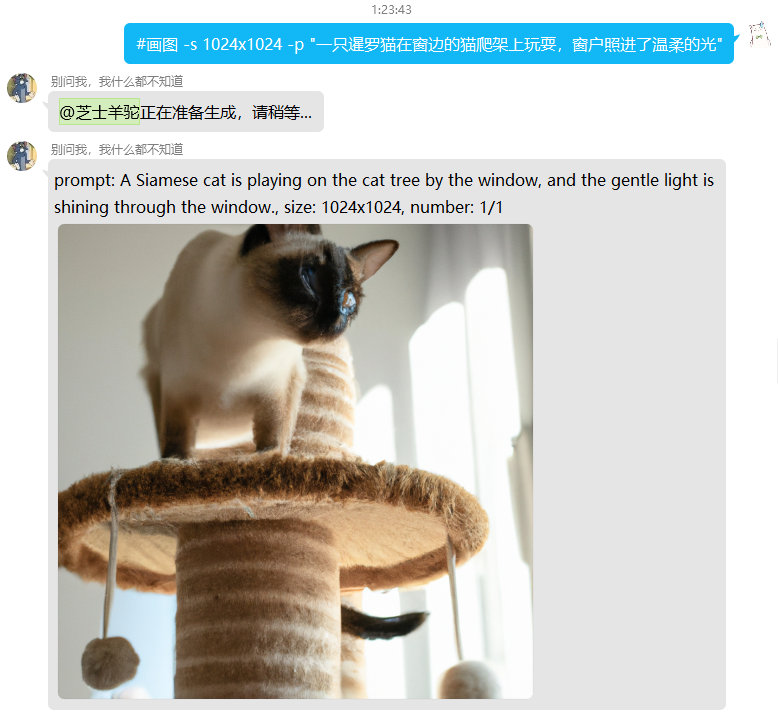
不过很可惜的是,OpenAI对图片的提示词进行了非常多的限制,所以有条件的话,最好可以在本地搭建stable diffusion,该平台有非常多优秀的模型。
最后附上一张文心一言的名场面复刻:
总结与展望
还有一些比较简单的功能就不再依次介绍了,总之,这个机器人虽然在OpenAI的加持下,已经非常有趣,但是仍然有很多功能优化不够到位。
在这个充满变革的时代,人工智能技术已经成为我们生活中的一部分,它正在逐步改变我们的世界。从医疗到教育,从生产到服务,AI的影响力愈发显著。通过对大量数据的学习和分析,智能系统为我们提供了高效、便捷的解决方案,使我们的生活更加美好。
未来的人类社会将进一步拥抱AI技术,许多传统行业将被重新定义,工作效率和生产力将得到前所未有的提升。而随着智能系统的不断优化,我们将更加重视人类情感、创造力和社会责任感等方面的发展。AI的推动下,我们的生活方式将愈发多元化,资源配置将更加合理,从而解决诸多全球性难题。
总之,人工智能技术的发展为我们的生活带来了广阔的前景,让我们充满期待。正如乔布斯所言:“我们生活的时代是如此神奇,我们必须抓住这个机会。”让我们携手共进,迎接AI技术为人类带来的更加美好的未来。
这个结尾其实是GPT-4编写的,顺便说一句,乔布斯似乎并没有说过这样的话...