又有一段时间没有写新文章了,在这段时间里,我悄悄把网站升级成https了,这从一定程度上保证了网站访问的安全性,除此之外我还写了一个爬虫。这个爬虫用来爬取某个不能说的网站上的视频。后来这个爬虫能稳定运行后,我又想采集另一个网站的视频,所以我就尝试把程序作为一个爬虫调度平台,将爬虫作为插件的方式来开发。以后有想采集新的网站、app的数据,就可以以插件的方式进行开发及添加。这样才符合所谓的“开闭原则”。
这篇文章不会主要介绍爬虫部分,也不会主要介绍多线程爬虫的调度和管理,只介绍Python的插件化设计。如果有需要了解爬虫或是这个系统的其他部分的,后面单独开文章介绍。
本文部分内容(有可能)会涉及到爬虫开发,在进行爬虫开发时,请注意以下法律问题: 1. 网站的使用条款:在爬取网站的信息之前,应该阅读并遵守网站的使用条款。 2. 个人隐私保护:爬取的信息中可能包含个人隐私信息,在使用这些信息时应该遵守相关法律规定。 3. 知识产权:爬取的信息中可能包含知识产权信息,应该遵守版权法。 4. 访问限制:某些网站可能会对爬虫进行限制,在爬取信息时应该遵守相关限制。 其他具体内容请查询你所在国家/地区的相关法律法规。
什么是插件化,为什么要插件化?
插件化的意思就是将程序的某些功能以插件的方式加入到程序中,或者通过插件对程序功能进行定制或扩展。将程序插件化可以使得程序动态的增减功能,同时也提高了程序整体的可维护性。
用游戏来打比方,游戏本体就是程序本体,插件就像是游戏的mod,通过安装插件可以增加、删除或修改游戏本体的内容。从而优化游戏或更改游戏内容。
将程序插件化的好处有很多,不过我没有去仔细地收集这些资料,就凭我自己的印象来说:
- 降低程序耦合度:从开发角度来说,最大的好处就是可以降低程序的耦合度,将程序中的各个模块分离开来,每个模块间单独运行互不影响,在对某个功能进行更新或修改的时候,也能尽量减少对程序的影响。
- 提高可扩展性:程序在开发时一般不太容易一次性完成所有功能的开发,所以系统在使用的时候,可能会有新的需求进入。如果把所有功能都集成到程序本体中,编写这些新的需求就很可能会对程序本体进行修改,这样就违反了开闭原则(对于开闭原则,我后面应该会再开一个“程序设计模式”的系列,又开一个新坑...),使用插件化设计就可以很好的解决这个问题,有新的需求直接开发一个新的插件,不会对原程序有任何影响。
- 易于维护:插件如果出现问题,结合日志系统就能很方便的对出现问题的地方进行定位。
- 其他好处: ...
想不到了,但是应该不止这些好处
简单的开发思路
要开发一个插件系统,首先应该开发一套用于插件开发的sdk。插件开发者基于这套sdk进行插件开发,最后的插件成品为软件包的形式,最后在本体系统中对检查通过的插件使用importlib.import_module进行载入。
详细一点的说,按照以下步骤来:
- 设定一个通用的插件目录,用于存放插件。同时也可以自定义插件分类,因为插件管理器是面向对象开发,所以可以对不同目录中的插件分类管理。
- 创建一个插件管理类,PluginsManager,这个类用于插件的加载,检查,卸载,初始化等等。使用类来对插件管理,基于面向对象的方法,这样的好处是每个插件管理类都是一个单独的对象,每个对象可以管理不同的插件,有不同的配置。
- 为插件设计一套存储元数据的方法,并设计一个标准初始化入口。在将插件载入完成后,插件管理器会分别执行每个插件的初始化函数,以此来对插件进行初始化。
- 创建一个全局的插件管理对象用于管理插件,同时也可以按需创建多个不同的插件管理对象。
- 设计一套sdk,供插件功能开发使用。
- 插件管理器的扩展设计,比如依赖检查、安全性检查、权限分类、高危操作监控等等。
有了这一系列开发思路,我们就可以按照这个思路来开发插件程序了。
着手实现插件系统
这个插件系统是我的爬虫平台中的一个服务的一部分,我会把这个插件系统的部分代码放上来供参考,不过因为一些不太好细说的原因,我可能会删掉一部分东西,或者对代码进行一些修改。但是按照我描述的步骤来一步一步操作,(应该)还是可以正常运行的。
首先是插件管理器类PluginsManager,我们先为这个类设计几个方法:
首先是初始化方法,在插件管理类初始化时,需要一个变量指定对应的插件目录,同时需要一个字典来保存载入的插件名称及对应包对象,然后需要为插件管理器实例化一个日志器(日志器Logger是这个插件平台的一个模块,负责日志管理,也是我自己开发的,不过这个日志器不是今天的重点,就不过多介绍了)用于管理插件管理器的日志。
代码如下:
1 2 3 4 5 6 | class PluginsManager: def __init__(self, plugins_floder): self.plugins = {} self.plugins_floder = plugins_floder self._logger = Logger("PluginsManager") sys.path.append(self.plugins_floder) |
在上述代码中,最后一行sys.path.append(self.plugins_floder)是为了把插件目录添加到python查找路径中,否则在导入包时python会提示找不到对应的包。
在完成插件管理器的实例化后,我们需要对插件进行导入。我为导入插件设计了两个方法,load_plugin和load_all_plugins,从名字就可以看出,这两个方法分别对应的功能就是载入某个插件和载入所有插件。载入所有插件的实现方法很简单,就是对插件目录下的所有包执行load_plugin就行,这里就不细说了,直接上代码:
1 2 3 4 5 6 7 | # 查找和加载所有插件 def load_all_plugins(self): self._logger.info(f'开始从 {self.plugins_floder} 加载插件...') # 获取plugins文件夹下所有插件 for plugin in os.listdir(self.plugins_floder): self.load_plugin(plugin) self._logger.info(f'插件加载完成, 共加载 {len(self.plugins)} 个插件: {list(self.plugins.keys())}') |
加载插件(load_plugin)的过程就比较复杂了,在介绍插件加载方法之前,先说说插件的格式。
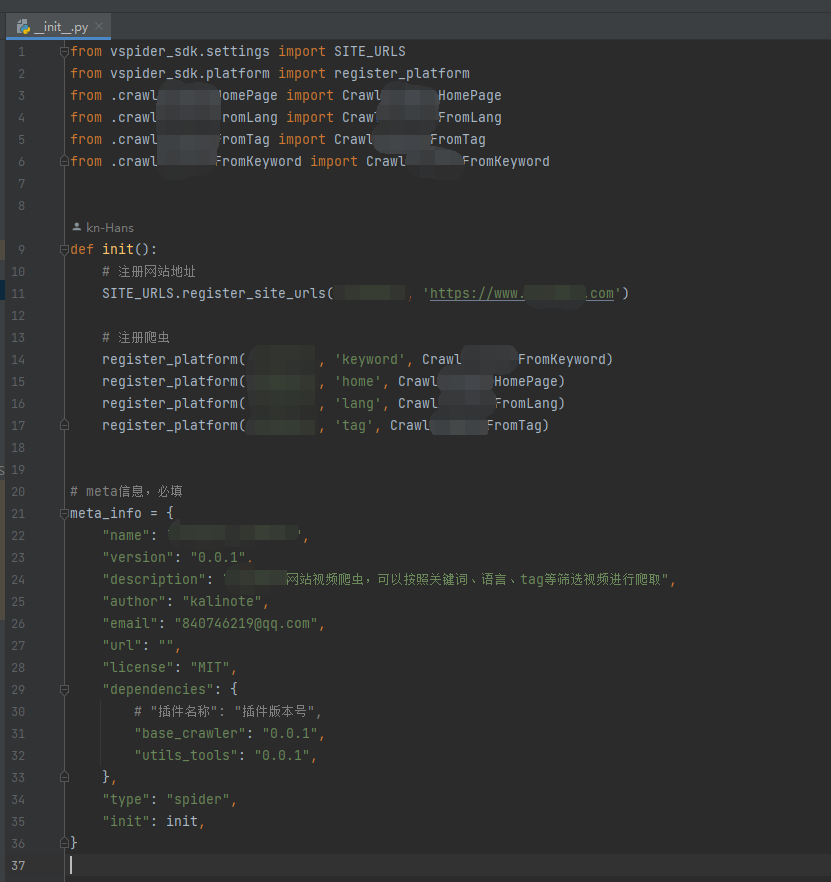
我设计的插件其实就是一个python的包,所以其最基本应该满足python包的格式,也就是说,在插件的根目录下应该有一个__init__.py文件。
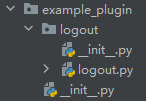
在导入插件前,我们需要找个地方来保存插件的元数据,以此来保存插件的名称、版本号、依赖插件、版权信息、程序入口等。既然我们python包里面包含__init__.py文件,那么把这些元数据保存在这里面即可。
在了解插件基本结构以后,接下来我们回到PluginsManager类,继续介绍加载插件的过程。
首先我们需要读取plugins文件夹(或指定的其他插件文件夹)中的所有文件(文件夹)信息,并逐个判断这些文件(文件夹)是否满足插件的条件(也就是首先得是一个文件夹、其次这个文件夹中应该有__init__.py文件,最后在__init__.py中应该有meta_info的字典变量)
在插件校验通过后,判断是否已经加载,如果已经加载则跳过处理下一个插件。
如果没有加载,接下来处理依赖插件。我写了一个方法read_metainfo_from_plugin(plugin_package_name)用于从__init__.py中获取meta_info,后面会介绍这个方法。在成功获取到meta_info后,从meta_info中提取到插件名称和依赖,并对依赖字典中的所有插件进行遍历添加。这里值得注意的是,插件名(meta_info中的name)和插件包名(插件根文件夹的名字)有可能是不同的,在这个程序中都是以插件名为准,所以不能单独使用依赖中的插件名称去遍历查找文件夹,而应该使用插件的meta_info中的name去查找,这里用到了一些简单的算法。在读取插件时,首先将所有依赖插件保存到一个list中,然后基于这个list去plugins文件夹中寻找对应名称的插件,找到一个就从list中删除一个,最后检查保存依赖插件的list是否为空,如果为空则表示所有依赖插件已经完成导入,否则说明有依赖插件加载失败,停止加载这个插件。
简单的思路就是这样,下面是对应的功能代码,可以参考上述思路结合代码中的注释进行理解:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 | # 加载plugins文件夹下包名(非插件名)为plugin_package_name的插件 def load_plugin(self, plugin_package_name) -> bool: self._logger.info(f'开始加载插件 {plugin_package_name}...') # 先判断是否是插件 plugin_dir = os.path.join(self.plugins_floder, plugin_package_name) if os.path.isdir(plugin_dir): plugin_package_name = os.path.basename(plugin_dir) # 检查是否有__init__.py文件 plugin_init_file = os.path.join(plugin_dir, '__init__.py') if os.path.isfile(plugin_init_file): # 满足插件的条件,获取meta_info meta_info = self.read_metainfo_from_plugin(plugin_package_name) if meta_info: # 判断是否已加载 if plugin_package_name in self.plugins: self._logger.info(f'插件 {plugin_package_name} 已加载') return True # 获取插件名、版本号(暂时先不检查)和依赖 plugin_name = meta_info['name'] # plugin_version = meta_info['version'] plugin_dependencies = meta_info['dependencies'] dependencies = list(plugin_dependencies.keys()) if dependencies: self._logger.info(f'插件 {plugin_name} 依赖 {dependencies} 插件,准备加载依赖插件') # 获取plugins文件夹下所有插件 for plugin in os.listdir(self.plugins_floder): plugin_meta_info = self.read_metainfo_from_plugin(plugin) if plugin_meta_info: if plugin_meta_info['name'] in dependencies: # 如果插件的依赖在plugins文件夹下,那么就加载这个依赖 if self.load_plugin(plugin): # 如果依赖加载成功,那么就把依赖从依赖列表中移除 dependencies.remove(plugin_meta_info['name']) if not dependencies: break if dependencies: # 如果依赖列表不为空,说明有依赖加载失败 self._logger.error(f'插件 {plugin_name} 的依赖 {dependencies} 加载失败') return False else: # 如果依赖列表为空,说明所有依赖都加载成功了 # 然后加载插件 try: plugin_module = importlib.import_module(plugin_package_name) self.plugins[plugin_name] = plugin_module self._logger.info(f'插件 {plugin_name} 加载成功') return True except Exception as e: self._logger.error(f'插件 {plugin_name} 加载失败: {e}') return False else: self._logger.error(f'插件 {plugin_package_name} 的meta_info读取失败') return False |
由于在处理依赖时使用到了递归,所以从理论上来说插件的依赖层数不能超过递归深度(如果没记错的话默认应该是1000),不过应该也不会有哪个插件依赖超过1000层吧...
接下来再看下刚才遗留的read_metainfo_from_plugin(plugin_package_name)这个方法。
这个方法的简单思路就是直接读取__init__.py,然后从文件中,通过正则表达式将meta_info以字符串的形式读取出来,最后再通过ast.literal_eval将读取到的meta_info字典字符串转换成字典。不过在转换前需要注意meta_info中的init键值对,这个键值对的值是python程序的入口,其类型是一个函数指针,由于我们在读取meta_info的时候是直接通过加载文件读取的,所以python并不能处理这个指针,所以我们需要通过正则表达式来把这个指针手动替换成字符串。
下面是这个方法的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | # 这个函数仍有一定的安全隐患,且功能尚不完善 def read_metainfo_from_plugin(self, plugin_package_name) -> dict | bool: plugin_dir = os.path.join(self.plugins_floder, plugin_package_name) if os.path.isdir(plugin_dir): plugin_package_name = os.path.basename(plugin_dir) plugin_init_file = os.path.join(plugin_dir, '__init__.py') if os.path.isfile(plugin_init_file): # 获取init中的meta_info try: with open(plugin_init_file, 'r', encoding='utf-8') as f: text = f.read() except Exception as e: self._logger.error(f'读取 {plugin_init_file} 时出错: {e}') return False match = re.search(r'meta_info\s*=\s*(\{.*})', text, re.DOTALL) if match: # 这里的init是一个函数指针,如果直接用这个字符串转换成json或者字典会报错,所以替换成字符串再转字典 reg_text = re.sub(r'("init"):\s*(\S+),', r'\1: "\2",', match.group(1)) return ast.literal_eval(reg_text) else: return False else: self._logger.error(f'没有找到包 {plugin_package_name} 的__init__.py文件') return False else: self._logger.error(f'包名为 {plugin_package_name} 的插件不存在') return False |
不过这个方法是我临时写的,而且使用正则表达式可能会有一定的安全风险,后面有空可能需要优化一下方案。
所有插件正确载入后,就可以对插件进行初始化工作了,我们在meta_info中留了一个键值对用于记录插件初始化入口,在进行初始化时调用其入口即可。
从逻辑上来说很简单,代码如下:
1 2 3 4 | # 初始化所有插件 def init_all_plugins(self): for plugin in self.plugins: getattr(self.plugins[plugin], "meta_info")['init']() |
通过SDK让插件控制主程序
SDK全称为Software Development Kit,中文名为软件开发工具包,顾名思义,这个东西是用于协助软件(在本文中是插件)开发的。
以调用日志器打印日志为例,设计一个SDK接口,并尝试开发一个插件来调用这个接口。先说一说简单的思路。
- 在主程序中新建一个包,并命名为vspider-sdk(vspider是我爬虫平台的名称),我们后面会把sdk的所有接口放到这个包里面。
- 在主程序根目录中创建一个setup.py,以供我们后面打包sdk时使用。
- 将vspider-sdk打包成whl文件。
- 在插件开发环境中安装vspider-sdk包。
- 调用sdk中的接口,实现相关功能。
下面我们就按照上述步骤来进行实际操作一下。
首先是新建一个sdk包,我目前软件的sdk结构如下:
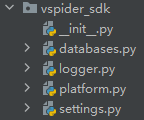
因为我之前在开发这个系统的时候没有考虑过开放给其他人开发插件,所以所有插件也都是我自己做的,我就给了插件极高的权限,并且没有增加插件安全性验证或者权限控制相关的程序,如果后期有需要我可能会追加这两个系统进去。
我sdk中的logger.py的代码如下,其中from logger.logger import Logger是导入主程序系统的日志器类:
1 2 3 4 5 6 7 | # 日志系统sdk from logger.logger import Logger # 获取logger def get_logger(logger_name): return Logger(logger_name) |
插件只需要先使用import导入vspider-sdk包,然后使用get_logger即可创建日志器。
接下来在主程序根目录创建setup.py,用于打包,代码如下(可以按照实际情况进行修改):
1 2 3 4 5 6 7 8 9 10 11 12 | from setuptools import setup setup( name='vspider_sdk', version='1.0.0', packages=['vspider_sdk'], url='', license='', author='kalinote', author_email='[email protected]', description='vspider的sdk开发工具,用于插件开发' ) |
其中package参数可以不用把整个主程序都打包进去,只用打包sdk即可,因为后续插件开发完成后需要配合主程序运行。
完成后的主程序目录结构如下:
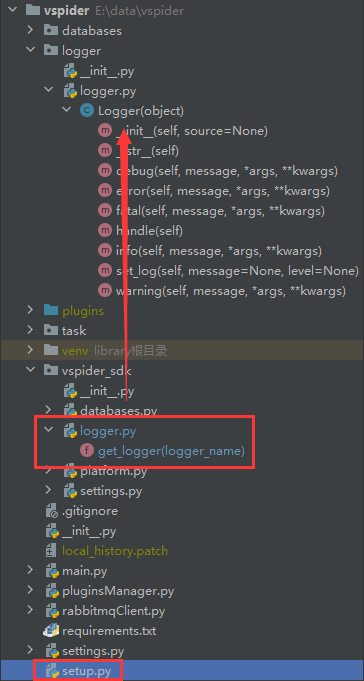
接下来通过setup工具,或者pycharm打包即可,得到sdk的whl包。
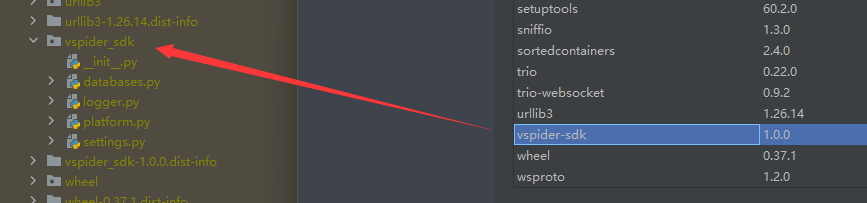
然后进入插件开发环境,导入这个包,我们就能在lib中看到sdk相关代码:
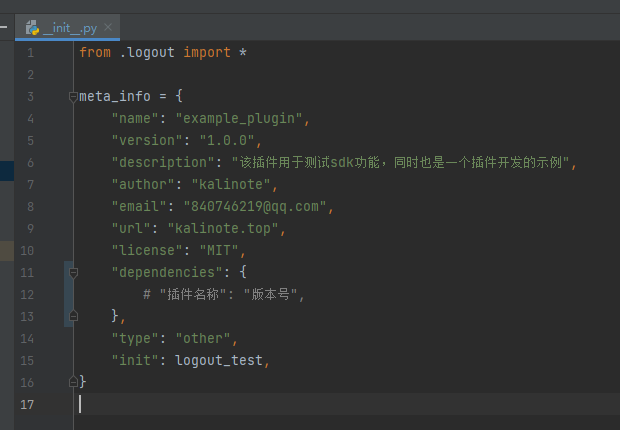
我们可以基于这个sdk进行插件功能的开发,比如我设计的个示例插件,功能是新建一个日志器,并打印三条日志,代码如下:
1 2 3 4 5 6 7 8 9 10 | import vspider_sdk.logger as logger def logout_test(): plugin_logger = logger.get_logger("test_plugin") plugin_logger.info('插件输出测试: info') plugin_logger.warning('插件输出测试: warning') plugin_logger.error('插件输出测试: error') # fatal暂时不做测试,等后面加了插件异常处理再说 # plugin_logger.fatal('插件输出测试: fatal', error_type=TypeError) |
并在__init__.py的meta_info中将init指向这个函数,这个插件的meta_info我在上面展示过了,就不重复展示了。插件最终结构也在上面放了图片了。
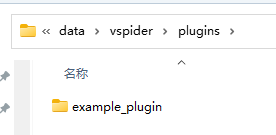
最后,在使用这个插件时,只需要把整个包放到plugins文件夹中即可:
主程序运行代码如下:
1 2 3 4 5 | if __name__ == '__main__': # 加载插件 plugins_manager.load_all_plugins() # 初始化插件 plugins_manager.init_all_plugins() |
运行效果如下:
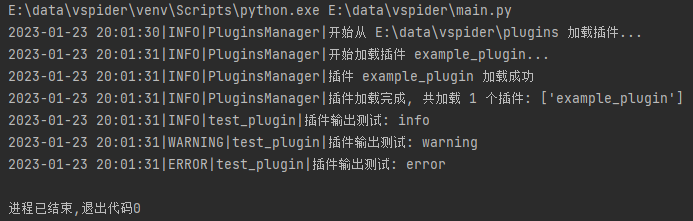
简单总结
至此,插件系统的开发就完成了。不过这个系统是我一时兴起的想法,而且是我自己系统使用到的,所以没有经过大量的可用性测试,也没有进行过安全性评估。如果在实际生产项目中引入类似的插件系统,一定要做好安全性和可用性的检测。
最后补充一句,依赖检测和自动导入依赖的功能我在我自己的系统中已经测试通过,就不再展示了。
合理利用这些程序设计方法,可以有效提高程序可维护性及可扩展性,在项目的迭代开发中可以起到极为有效的作用。
补充内容
我给我的爬虫系统设计了一个sdk接口,功能是注册爬虫。插件只要调用这个接口,就可以在系统中注册为一个爬虫,爬虫调度器在对爬虫进行调度时就会读取到对应的插件。
这样一来,以后如果我需要新增某个网站或app的爬虫,只需要开发一个新的插件即可。